
DeepSeek开源新模型,让AI睁眼看世界
10月20日,DeepSeek开源了它的新模型。不是我心心念念的DeepSeek R2,而是一个他们称之为DeepSeek OCR的模型[1]。
刚刚看到这个消息,我根本没有仔细去看,OCR嘛,我觉得自己常用的MinerU就已经足够好用了。今天打开这个模型的论文,看到论文摘要,不禁眼前一亮:靠!还能这样?真是脑洞大开啊。
脑洞大开的压缩方式
现在长上下文已经是模型智能的一个瓶颈,上下文越长,所费的token也越多,推理成本直线上升。DeepSeek想了一个方法,把长文本转成图片,比如说有一个1万字的文本,大约需要10000个token,转成一个A4大小,300个dpi的图片,只需要100个token。这可相当于压缩了100倍。推理成本直接缩水4个数量级。
另外,在研究文本和图片互转时,DeepSeek顺便也能将图片转成文本。结果发现识别效果比人家专业做OCR的表现更好。
DeepSeek能像真人一样,看书不是逐字逐句地读,而是扫一眼大致理解。这从某种意义上来说,就是对信息进行了高效地压缩,能很快抓住重点。
效果怎么样?
压缩还原能力上,数据表明,当文本标记数量不超过视觉标记10倍时(即压缩比<10倍),模型解码(OCR)精度可达97%;即使在20倍压缩比下,OCR准确率仍保持在60%左右。
OCR性能上,每页只用800个Token,识别效果优于MinerU2.0。而后者会消耗大约6000个Token。
能高效识别多图、多表格的复杂图片。能处理近百种语言。
这么做有什么意义?
我要先把文字转成图片,用图片进行推理,然后再把图片转成文字输出。绕上这么一大圈,只是为了减少推理成本吗?
省钱
首先要肯定的是,用图片代替文字输入的确节省成本。而且不光是推理成本。在显存占用上,也是节省惊人,比如你有40G的显存,当前长文本方式,能处理1万字,而换成图片,可能是上百万页A4大小的图片。
省事
人类知识载体五花八门,就文本格式来说,就有PDF、Word、WPS、HTML、Latex……每种都要专门的解析器,再加上图表、标注、字体等等,资料格式、表现形式和使用语言都千奇百怪,想要整理成统一的格式,工作量非常大,现在好了,全部转成图片,一张JPG搞定所有。
拟人
通用人工智能,往往会尽量模仿人类的行为。用图像来处理信息,刚好与人类记忆有某种形式上的相似性:
人类记忆的特点是随时间推移,记忆会越来越模糊。这里可以用图片的分辨率来模拟时间的流逝。最近一轮用高清的图片,昨天图片用普通的分辨率,上周的用低分辨率,去年的用模糊的图片即可。
token数随时间指数下降,但关键信息仍留存,实现可微调的“生物式遗忘”。显存也不再随对话轮数增长。
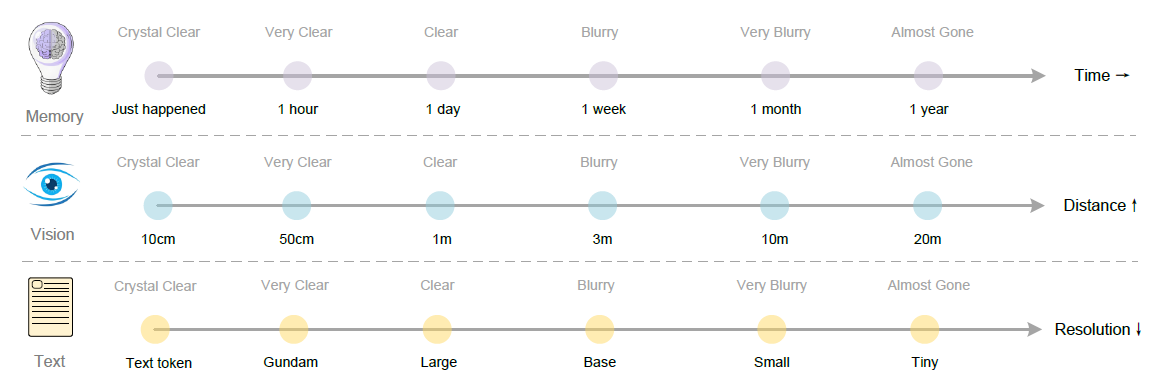 上面是论文中的一张插图,类比人类的记忆力。遗忘机制是人类记忆最根本的特征之一。上下文光学压缩法通过将历史对话轮次渲染成图像进行初级压缩,随后逐步缩小陈旧图像的尺寸实现多级压缩——在此过程中标记数持续递减,文本渐趋模糊,从而完成对文本的遗忘。
上面是论文中的一张插图,类比人类的记忆力。遗忘机制是人类记忆最根本的特征之一。上下文光学压缩法通过将历史对话轮次渲染成图像进行初级压缩,随后逐步缩小陈旧图像的尺寸实现多级压缩——在此过程中标记数持续递减,文本渐趋模糊,从而完成对文本的遗忘。
怎么做到的
听起来不错,但是有一个疑问一直令我困惑。
我有一个1万字的文章,假如分成了1万个Token,我使用它进行推理时,其实是基于这些Token之间的关系,我把每个Token想象成一个单元,如果这篇文章打印到一张A4纸上,然后变成了图片,既然这张图只需要100个Token就可以进行推理,就是相当于是基于100个单元之间的关系进行推理,是不是意味着有9900个关系被丢失了?
让我们先看看论文中提到的创新点:DeepEncoder
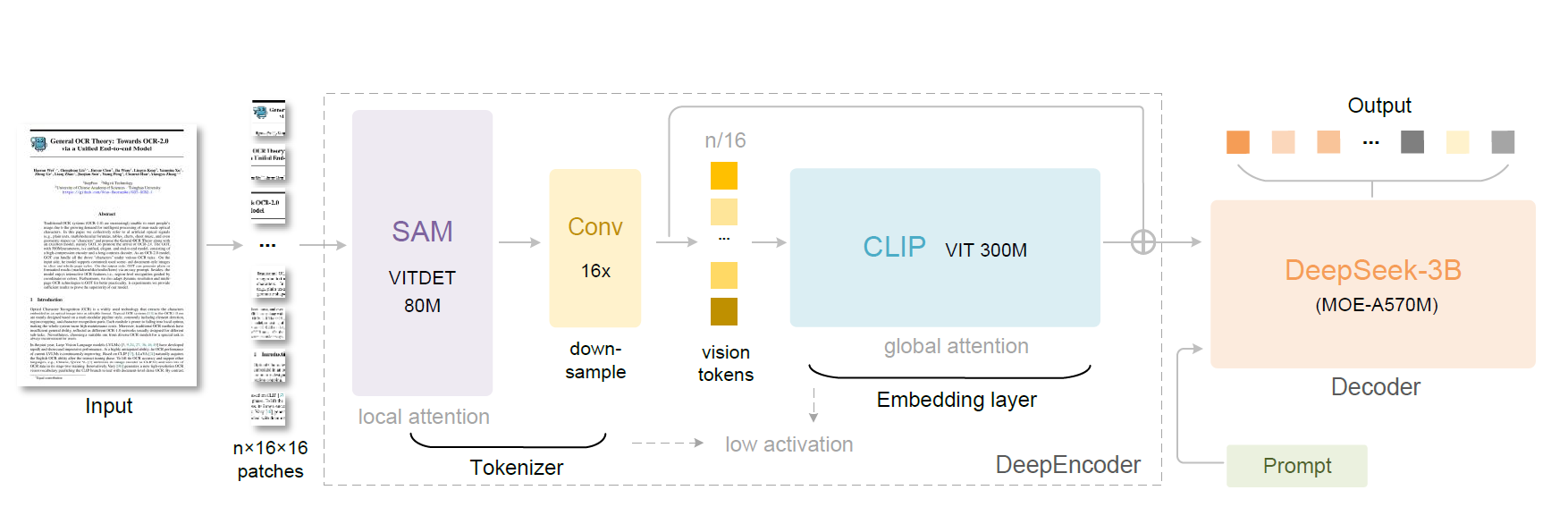
上图是DeepSeek-OCR的架构。DeepSeek-OCR由DeepEncoder和DeepSeek-3B-MoE解码器组成。
DeepEnconder
DeepEncoder是DeepSeek-OCR的核心,包含三个组件:
- 以窗口注意力主导感知的SAM
- 采用密集全局注意力实现知识编码的CLIP
- 连接二者的 Token压缩器
上面的SAM是Meta在2023年发布的Segment Anything论文( arXiv:2304.02643)中的图像编码器(image encoder),Deepseek把它当作“窗口注意力局部特征器”来使用。有8000万参数。
上面的CLIP是OpenAI 2021 年发布的Contrastive Language–Image Pre-training(arXiv:2103.00020)。这里把它作为全局注意力编码器用。它的参数有3亿个。
这样DeepEncoder一共约3.8亿个参数。
连接SAM和CLIP的是一个16倍Token压缩器。
假如我们输入一个1024*1024的图片,先使用SAM,将图片切成16*16的小块,一共4096个,每个就是一个Token。将这4096个Toekn,通过压缩器压缩成256个Token。然后将它输入CLIP进行训练,形成模型。
DeepSeek-3B MoE-A570M
在具体使用时,我们需要用到上面的解码器。比如说,我们已经拿到了DeepSeek开源的权重文件,在输入我们的提示词(提出问题和要求)后,DeepSeek就使用上面的解码器通过权重文件将生成的Tokenl转译成文本输出。
MoE就是混合专家模型,具体来说,上面的名称就是“3B 参数、只激活 570M”的 MoE-Transformer解码器。
现在再回到前面的疑问,是不是有99000个Token丢失了呢?
不是!
一个文本的Token和一个视觉Token,后者的容量比前者大的多,信息熵也要高的多。
用一个生活中的例子就是,你可以用几万字形容一个人的外貌,也可以用一张照片来表示。这其实涉及到信息场理论,连续的文字可以理解成一维信息而图片相当于提升了信息的维度。
token之所以能减少,推理加速,并不是凭空多出了许多信息熵,而是在训练时已经预付了信息熵。视觉 token 的“高熵”是训练阶段用算力硬塞进去的。
普通LLM,是用Transfomer计算一个字一个字之间的关系,而VLM是用Transformer计算一小块图一小块图之间的关系。
论文中显示,DeepSeek OCR比传统VLM还有一个小巧思,就是使用传统OCR的结果,结合已经产出的模型自我训练(self-training),优化模型,给图片打标签。  上图左边是原图,右边是OCR出的结果,我们能明显看出,右边不光是识别出文本,还将文本的位置和性质加上了精准的标注。
上图左边是原图,右边是OCR出的结果,我们能明显看出,右边不光是识别出文本,还将文本的位置和性质加上了精准的标注。
感想
我觉得DeepSeek这次开源的模型,被它的名字耽误了。明明是个龙傲天,却取名叫小帅。
某种意义上,DeepSeek OCR和光学识别(OCR)技术无关,它关注的不是将图片转成文字,而是图片中蕴含的信息。
它也与其实的LLM不同,别的大模型是将世界转录成文本,然后试图通过这些文字间的关系理解这个世界,而DeepSeek OCR直接理解这个世界。
想象一下吧,当别的AI通过书本学习知识时,新版的DeepSeek可以通过眼睛去感受这个世界。这是通向AGI的另一种尝试啊。
现在我正在下载权重文件,试着按github上的指南尝试一下。也不知道我的3060能不能跑的起来。