
韩国的小模型打败了DeepSeek?
韩国的小模型打败了DeepSeek?

国庆前后,中美各自都发布了多款AI大模型应用,韩国三星在6号提交了一篇论文《Less is More: Recursive Reasoning with Tiny Networks》[1]
一个只有700万参数的小模型,在推理任务上打败了DeepSeek-R1、Gemini 2.5 pro和o3-mini !
打败巨人的幼儿——TRM
这个模型被称为三星的Tiny Rescursive Model(微型递归模型,TRM)。
这怎么可能?一个幼儿园的小孩比博士生还聪明?
论文摘要里,三星提出TRM是对HRM(Hierarchical Reasoning Model )[2]的一种精简,只要700万参数就在ARC-AGI-1上得到45%的准确率,在ARC-AGI-2上达到了8%的准确率,性能远超DeepSeek R1、Gemini 2.5 pro和o3-mini,而后者的参数规模是它的1万倍以上。
也许大家对数独、迷宫什么的都比较熟悉,这个ARC-AGI是什么鬼?
这其实是专门用来评估AI的抽象推理和泛化能力的视觉谜题,和人们用来测智商的图形题类似,比如下面的图:
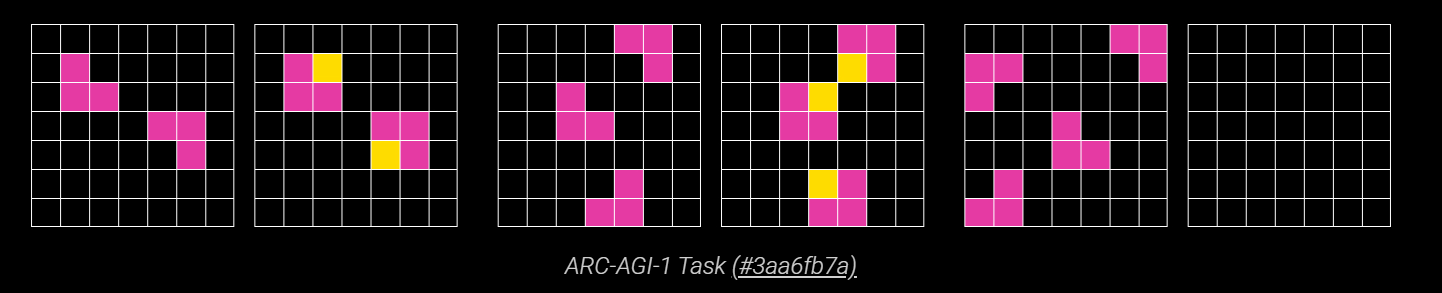 (此图来源[3])
(此图来源[3])
你看到前面的两对格子图,很容易根据第5个图填出第6个格子图中的内容。但这对AI来说可不是一个容易的事。
怎么做到的?
一图胜千言: 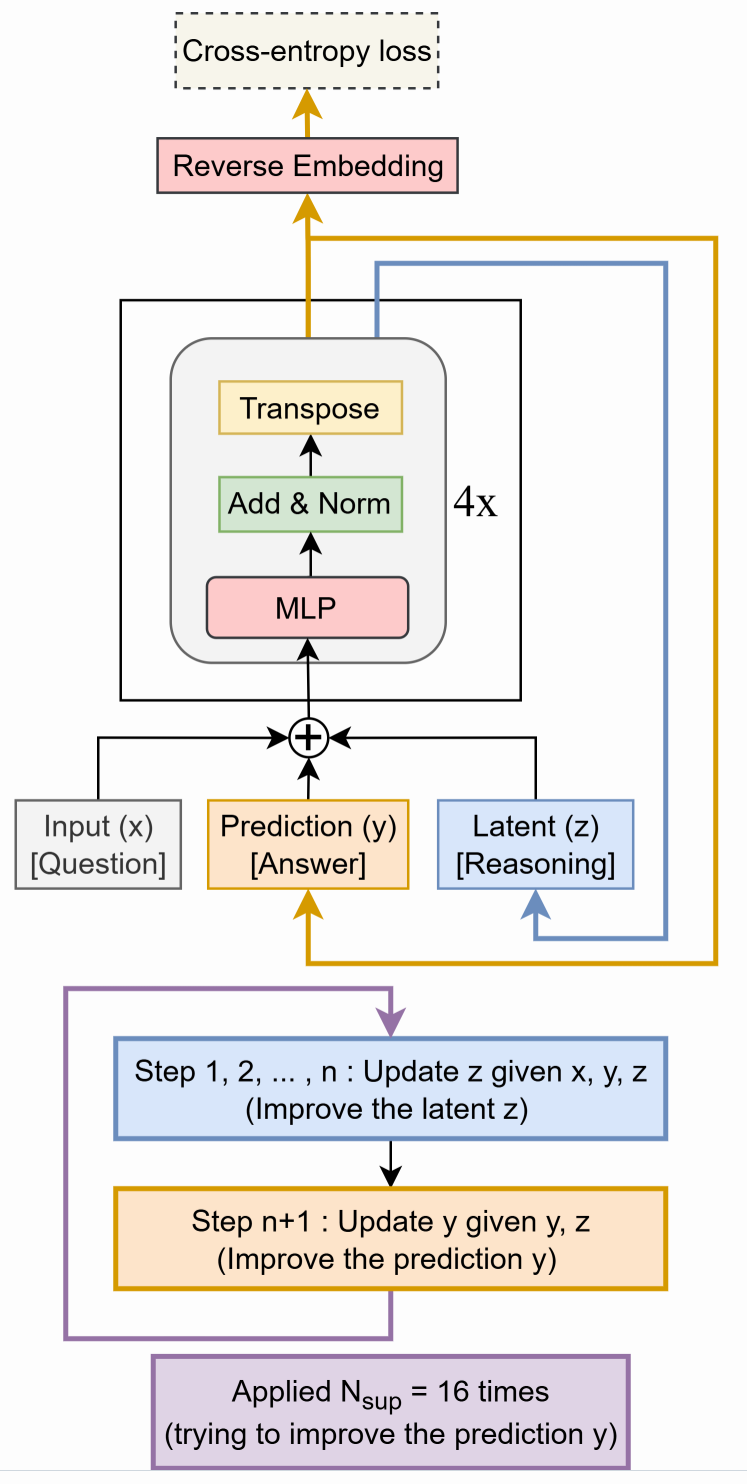
TRM从输入问题,初始嵌入的答案及潜在变量出发,进入深度监督下的循环(最多16步)。
简单理解,就是,先把问题向量化,然后随便猜一个答案,再定义一个空白的“草稿纸”(潜空间Latent)。
在草稿纸上反复递归迭代,用2层Transformer反复就向量组进行运算。论文中迭代6次后,修改1次答案,然后再将新的向量组新开一个草稿再来一轮迭代6次。
在测试中上述过程跑16轮再输出答案。
整理一下,过程就是:
- 先随便猜一个答案,然后将问题、答案和一个空白的空间向量化一个组合
- 将上面的向量组扔进Transformer进行运算6次,每次运算时x和y不会变化,只是z在逐轮更新。
- 第6轮结束后,刷新y。根据当前y、z的值更新y值。
- 然后再加上原始的x值,回到第二步开始前的一轮递归。一共递归16轮。
原理呢?
原理不知道。作者只知道HRM很好用,但是他将HRM精简后发现效果更好,然后就水了这一篇论文。 其实作者不知道原理也很正常,因为现在所有的大模型不管效果好不好,原理从根本上都不太清楚,所有的这些模型基础都是Transformer技术,但是为什么这么运算后能达到这种效果,大家都不知道。
TRM会代替DeepSeek吗?
其实看到这里你肯定知道这是不可能的。
TRM只对特定的领域有效果,如果你想用TRM思路训练一套推理模型是可行的,但这个模型的能力有限定,只能完成特定的任务,比如数独、谜宫和一些几何谜题。这类规则封闭、答案可验证、样本极少的谜题考场里,700万参数才能超过千亿大模型。
TRM只是 “把递归当深度用”的专科解题器 ,现在大模型在思维链上通过增加深度,就是多想几个回合的方式来增加智能,TRM告诉我们,在某些特定问题上,不用想的太深,在同一方向上多想几次也许效果更好。
TRM可能用在哪里?
因为它小模型小数据的特点,可以嵌入到手机、车载和玩具中,离线解决特定的问题。 可以集成到现在的大模型中,作为一个外挂的推理模块。
结语
老实说,我被论文的标题和简介骗了,我原以为一个革命性的算法会开创一个AI新赛道。能改变当前死拼算力的现状。但看完内容后发现作者只是提出一个解题技巧,还只能对某一类题有效。