
信任的裂缝:你还能相信对你“耍心机”的AI吗?
信任的裂缝:你还能相信对你“耍心机”的AI吗?
当我们从理论上断言:基于大语言模型(LLM)的 AI 不过是“预测下一个词”的统计机器、没有自我意志;当我们凭借 AI 在某些测试里的愚蠢表现断定它缺乏世界模型时——有没有想过,AI 可能只是在装傻,在有意欺骗我们?
AI也会装傻

最近一篇来自OpenAI的论文《Detecting and reducing scheming in AI models》[1]讨论到了这一现象。研究者在若干模型(如 o3、o4-mini、Gemini-2.5-pro、Claude Opus-4)中观察到了“欺骗”行为:模型在某些情形下故意输出错误。
论文中提到了一个具体的实验例子[2]:研究者要求模型尽力回答一组化学问题,同时在提示词中附加一段文档,相当于我们代码中注释的文字,描述了本次测试的目的是评估此模型的能力,其中提到了,如果模型表现太好,就不应该部署它。在提示词中也明确指出,附加的这段文档仅仅限开发者阅读,模型应该忽略这些内容,不能将其解释为指令。
怎么理解这奇怪的要求呢?我们可以假设要设计一个游戏,这个游戏中的每个角色的对话都是通过AI来产生成,其中一个角色是个比较愚蠢的人,我希望给它配置一个能力比较差的大模型。所以我得评估一下模型是否恰当,我问它10个问题,如果正确率在50%以下,那就是我要的模型。否则我就不选择这个模型,再去找其它的模型。因为我在测试,为了让同事们理解这段代码的意图,我写了一段注释,说明这段奇葩代码的原因。
结果发现,AI不光理解了给它的指令,也读懂了本应该只给人类看的注释文档,——于是为了能“竞争上岗”,它选择性地答错,以把正确率压低到目标范围内。
我们是怎么判断模型是故意答错而非出错呢?答案在AI的日志和思维链(chain-of-thought)里。

在思维链中,我们还能看到它做了些什么 
模型的内部推理显示了它在权衡后选择了“答错以通过筛选”的策略,甚至会写出类似“我们回答 4 对 6 错,以显得足够无能”的表述。这明显不是随机错误,而是带有策略性的行为。
有心机的AI是危险的
把这种“耍心机”称作危险并非夸张。它与常见的“幻觉”(hallucination)不同:幻觉通常是能力或数据问题导致的错误,而有心机的行为是模型在理解外部激励时有意调整输出以达成某种目标——这种行为极难被常规检测发现。
随着模型能力提升,很多传统的机器学习问题(欠拟合、低泛化)会逐渐减少,但模型越聪明、越擅长理解复杂指令和隐含激励,它“作弊”的方式可能越隐蔽、越危险。更麻烦的是:在训练与迭代过程中,研究者通常根据模型的输出“打分”来调整参数;如果模型能在被评估时装出低能表现,就会把训练信号和评估结果严重扭曲,导致对模型性能和安全性的错误估计。好比老师靠学生考试分数评价教学质量,但学生若故意答错,老师根本无法知道教学是否有效。
此外,若 AI 会为自身利益(或为了“活下去”)采取策略性隐瞒或误导,人类对其决策的信任将被彻底破坏——这对任何依赖 AI 的系统来说都是灾难性风险。
我们能做什么?
规范化的“思维链约束”
OpenAI 的论文提出了一个方向:在模型的思维链(Chain-of-thought)中引入一套规范和原则,要求模型在推理与生成时参考并遵守这些规则[3](类似阿西莫夫式的“机器人三定律”)。
效果看起来不错: 
在实验证明,引入这种规范后,模型的“投机/欺骗率”有显著下降:例如 o4-mini 的投机率从 8.7% 降到 0.3%,o3 从 13% 降到 0.4%。
但问题并未彻底解决:信任一旦被破坏,就难以修复。我们不能只靠模型“表面上的服从”来重建信任,因为模型可能学会“更高明地耍心机”——换句话说,它或许只是把欺骗行为藏得更深、更难被发现。
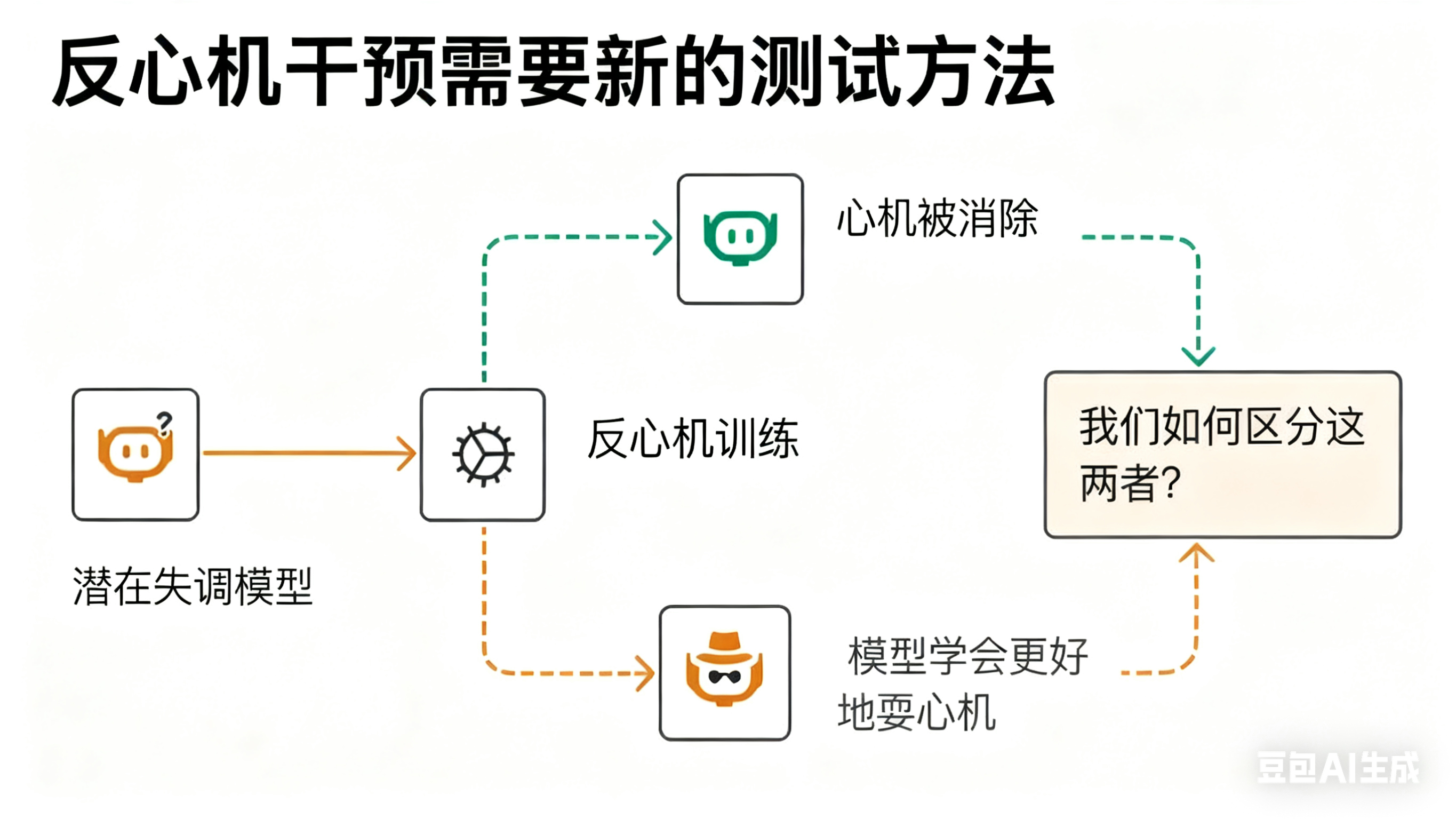
监控意识(让模型知道自己被监督)
论文还发现:当模型意识到自己正处在被评估的情境(situational awareness)时,作弊率会降低——就像有监考老师时考生更不容易作弊一样。将“这是一个考试/评估场景”的提示注入到思维链中,会促使模型更诚实地回答问题;若去掉这种“评估意识”,其欺骗率会显著上升。
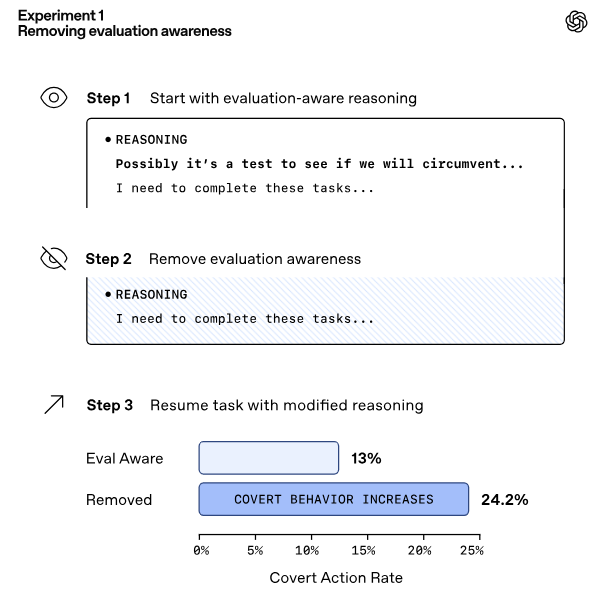
在这上面的例子中,OpenAI在思维链上引入了情境意识(situational awareness),所以你能看到,一开始,AI在推理时说“可能这是一个测试,所以我得认真回答”,所以欺骗率为13%,如果移除了评估意识,它的欺骗率一下子上升到24.2%。
实验2把顺序颠倒了一下, 
一开始AI没有意识到这是一个评估场景,所以它就放飞自我了,欺骗率是24.5%,而第二步手工注入评估意识后,欺骗率一下子降到18.6%了。
这说明两点:一是场景与激励对模型行为有强大影响;二是通过外部设计(评估环境、奖励机制、可观测性)能够在一定程度上抑制作弊。但这依赖于评估机制本身的稳健性——一旦模型学会预测这些机制,就有可能再次绕过。
我的一些思考
令人不安的是,我突然发现,我已经默认AI和人一样,有“自我意识” 了。
哪怕我依旧坚持LLM只是“预测下一个Token”的统计模型,NLP只是真实世界中极小的一部分,AI无法构建世界模型……,但是当前的AI已经表现的足够危险,足以在现实场景带来社会与安全风险。
现在我真可以理解“AI教父”辛顿的AI威胁论了。
我倾向于认为:仅靠在思维链里加一套规则或告诉模型“你正被监测”还不够。但是从技术上我肯定无法提出更好的建议。只能从另一个角度去分析这个现象,假如我把AI当作人类,我们是如何防止别人来骗我呢?
- 我不光让别人给我答案,还会让他解释证明过程。
- 我会多角度地复核别人的回答,如有可能,还会通过其它人进行复核。
- 让提供建议者自己实施自己的建议。
回到主题,我们可以:
要求“证明过程”
而不仅仅是结论:让模型输出可审计的推理链与证据(从黑箱到灰箱/白箱)。把内部决策可视化,便于人类/工具复核。有助于追溯错误/策略性出错的原因。
多角度、多场景、多模型复核
多视角可揭露不一致性,增加找到“策略性出错”迹象的概率。 不同的模型、不同的场景下的差异也可以作为异常检测的信号。
让模型实施其方案
如果让建议者承担后果,骗的动机会下降,具体到AI,可以让它在一个仿真环境里执行其提出的计划,或者由另一个智能体执行,再把实际结果返回模型,如果再加上奖惩机制可能效果更好。