
阅读《Modern Generative AI with ChatGPT and OpenAI Models》
阅读《Modern Generative AI with ChatGPT and OpenAI Models》
开始:2023-09-02
拥抱AIGC – 【美】瓦伦蒂娜·阿尔托Modern Generative AI with ChatGPT and OpenAI Models – Valentina Alto

类似于ChatGPT属于生成式AI(Generative AI)下图显示这些研究l领域是关系: 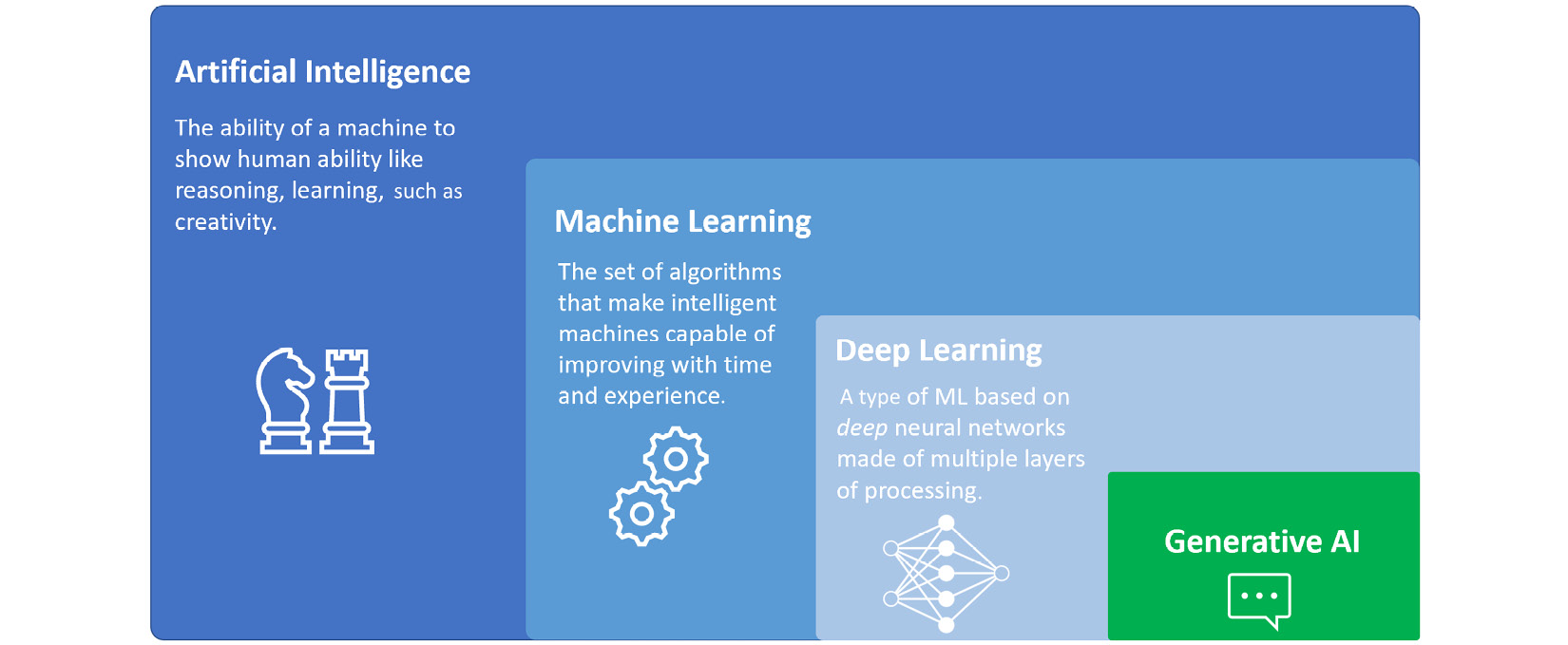
- AI:机器类似于人类,有推理学习能力,有创造性,并能与环境互动
- ML:是AI研究方向的一个分支,专注于创建算法和模型,使这些系统能够通过时间和训练来学习和改进自己。ML 模型从现有数据中学习,并在增长时自动更新其参数。
- DL:DL是ML的一个分支,基于神经网络,特别适用用计算机视觉或自然语言处理(NLP)等领域。
- 生成式AI:是DL的一个分支,它使用神经网络,但不用来对现有数据进行聚类、分类或预测,而是用来生成全新的内容。
生成式AI模型与普通DL的区别在于,普通DL在将数据进行标签后进行分析,然后会产生一个模型。当我们遇到一个新的数据,我们会根据这个模型,将这个数据归类到一个标签中,比如,医生用深度学习来研究肿瘤的CT片,根据成千上万张CT片,我们可以得到一个模型,然后再给这个系统输入一个新的CT片,它能根据以前学习的内容,判断这张CT片是否患有肿瘤,或者是哪种肿瘤。
生成式AI可以用来
- 产生文本:它能用自己的语言产生一些全新的内容。
- 图像生成:最早使用生成式对抗网络架构,即:Generative Adversarial Network (GAN)架构。OpenAI则引入了一种新的AI模型,可以从自然语言的描述中生成图像。
- 音乐生成:
- 视频生成:
backpropagation 反向传播算法
我的简单理解:对于平面直角坐标系中的一系列点,我们尝试求出一个公式,假定这是一个多元二项式,对于正向传播算法来说,就是用用一系列的参数去尝试,看是否拟合这个曲线,而所谓的反向传播算法,是根据正向传播的结果,量化拟合度,并根据这个量以一定的规则在调整参数,然后再用调整后的参数重复这一过程。
VAE
变分自编码器(Variational Autoencoder,VAE)
变分自编码器(Variational Auto-Encoders,VAE)作为深度生成模型的一种形式,是由 Kingma 等人于 2014 年提出的基于变分贝叶斯(Variational Bayes,VB)推断的生成式网络结构。 https://arxiv.org/abs/1312.6114 - [1312.6114] Auto-Encoding Variational Bayes
简单地说, 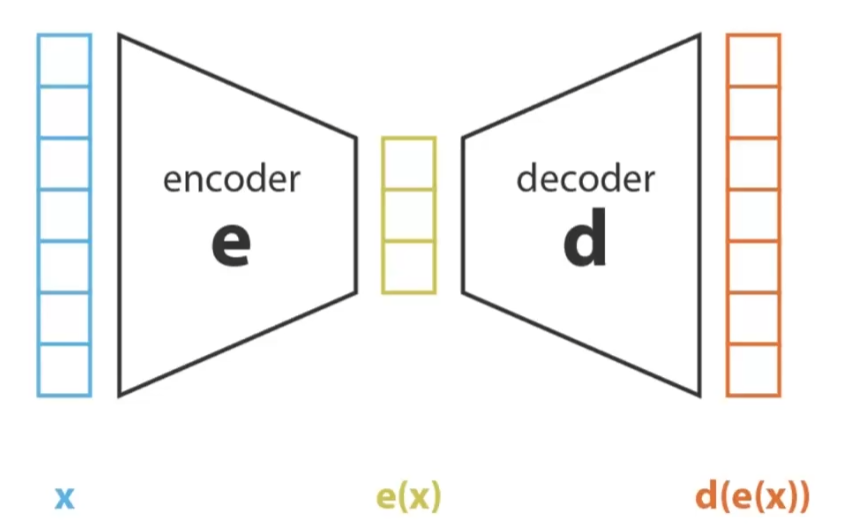 VAE是将左边的值编码得到向量e(x),然后通过解码得到d(e(x))
VAE是将左边的值编码得到向量e(x),然后通过解码得到d(e(x))
举例如下: x是一张猫的照片
编码过程是得到一系列的向量参数,e(x)可能就是: {毛发颜色:黑色,毛发长度:短,品种:英短,状态:侧躺……} 这样一组向量
d(e(x))则是一个解码过程后的结果,它会是机器生成一张图,这个图是根据上面的e(x)中向量生成的
VAE的特点在于,上面的那组向量值,是一个概率,比如毛发颜色是6080%的黑,品种是英短的可能率在8090%
VAE的关键创新是引入潜在空间的概率解释。编码器并不学习将输入以确定性的方式映射到潜在空间,而是将输入映射到潜在空间上的概率分布。这使得VAE可以通过从潜在空间进行采样并将样本解码回输入空间来生成新样本。
VAE为生成式人工智能领域的快速发展奠定了坚实的基础。事实上,仅仅一年之后,Ian Goodfellow便提出了GAN。与主要元素是编码器和解码器的VAE框架不同,GAN由生成器和判别器两个神经网络组成,二者采用零和博弈的方式合作。
GAN
生成对抗网络(Generative Adversarial Network,GAN)
GAN由生成器和判别器两个神经网络组成,二者采用零和博弈的方式合作。
生成器生成假数据(例如新图像),旨在模仿真实数据(例如猫的图像)。判别器接收真实数据和假数据,并尝试区分二者,扮演着评判者的角色。
在训练期间,生成器会尝试生成数据以欺骗判别器,让判别器将假数据误认为是真实数据,而判别器则尝试变得更擅长区分真实数据和假数据。二者会在对抗式训练(adversarial training)的过程中一起训练成长。
随着训练的持续,生成器变得更擅长创建看起来像真实数据的假数据,而判别器变得更擅长区分真实数据和假数据。最终,生成器会变得非常擅长创建看起来像真实数据的假数据,即使判别器也无法看出真实数据和假数据之间的区别。
OpenAI是由Elon Musk,Sam Altman,Greg Brockman,Ilya Sutskever,Wojciech Zaremba和John Schulman于2015年创立的研究机构。
Generative Pre-trained Transformers (GPT).生成式预训练的Transformers
2019年发布了GPT-2,这个版本基于Reddit中至少得到3个赞的语料,12亿参数 2020年发布了GPT-3,1750亿参数
一些术语:
- Tokens: API 用于处理输入提示的单词片段或段。可以理解成对话中的关键词,但这个关键词并不一定是完整的单词,可能是一段句子,一般的准则是,token长度相当于你输入内容的3/4
- Prompt:提示,比如,你在问题时,可以说“以一个初中生可以听懂的话来表达”
- Context:上下文
- Model confidence:模型置信度,是指 AI 模型分配给特定预测或输出的确定性或概率级别。在 NLP 的上下文中,模型置信度通常用于指示 AI 模型对其对给定输入提示的生成响应的正确性或相关性的置信度。
- AGI(Artificial General Intelligence)通用人工智能 ,一般来说,AGI旨在具有学习和执行各种任务的能力,而无需特定于任务的编程。 -DRL(Deep Reinforcement Learning )深度强化学习,是ML(machine learning,机器学习)的一个子集,将RL(Reinforcement Learning,强化学习)与深度神经网络相结合
OpenAI仍有一些可以针对用例量身定制的方法:
- 第一种方法已嵌入模型的设计方式中,其可以在少数学习方法中为模型提供上下文。也就是说,用户可以要求模型基于之前写过的一篇文章生成一篇模板和词库相似的文章。为此,用户可以对模型进行生成文章的提问,并提供前一篇文章作为参考或上下文,以便模型针对文章请求做更好的准备。
- 第二种方法更复杂,那就是微调(fine-tuning)。微调是使预训练好的模型拟合新任务的过程。
原来我以为微调是RAG的基础,但是经过查询发现不是
FT与RAG的区别
FT与RAG的区别
OpenAI中的fine-tuning(微调)和Retrieval-Augmented Generation(RAG,检索增强生成)是两种不同的技术,但它们可以结合使用以提升模型性能。以下是它们的关系和区别:
1. Fine-Tuning(微调)
定义:微调是指在预训练模型的基础上,使用特定领域的数据进一步训练模型,使其在该领域表现更好。
特点:
- 数据需求:需要大量标注数据。
- 灵活性:模型可以学习特定任务的特征。
- 应用场景:适用于需要高精度和特定领域知识的任务。
优点:
- 模型在特定任务上表现更好。
- 可以适应特定领域的语言风格和术语。
缺点:
- 需要大量标注数据。
- 训练成本高,时间和计算资源消耗大。
2. Retrieval-Augmented Generation(RAG,检索增强生成)
定义:RAG结合了生成模型和检索系统,生成答案时从外部知识库检索相关信息,增强生成内容的相关性和准确性。
特点:
- 数据需求:依赖外部知识库,不需要大量标注数据。
- 灵活性:动态结合最新信息,适应性强。
- 应用场景:适用于需要实时信息和广泛知识的任务。
优点:
- 生成内容更相关和准确。
- 无需大量标注数据,成本较低。
- 能结合最新信息,适应性强。
缺点:
- 依赖外部知识库的质量和覆盖范围。
- 检索过程增加计算开销。
3. 关系与结合
关系:
- 互补性:微调提升模型在特定任务上的表现,RAG增强生成内容的相关性和准确性。
- 结合使用:微调后的模型可以与RAG结合,进一步提升性能。
结合使用示例:
- 微调模型:在特定领域数据上微调预训练模型,使其掌握领域知识。
- RAG增强:在生成答案时,结合外部知识库检索相关信息,确保生成内容准确且相关。
总结
- Fine-Tuning:通过特定领域数据训练模型,提升其在特定任务上的表现。
- RAG:通过检索外部知识库,增强生成内容的相关性和准确性。
- 结合使用:微调后的模型与RAG结合,进一步提升性能,适用于需要高精度和实时信息的任务。
Transformer架构
前身是RNN结构,而RNN之前流行的是ANN,ANN是前馈式,就是每一个隐藏层的输出都是下一个隐藏层的输入,而且不保留前面那些隐藏层的信息。RNN则保留了前面所有隐藏层的信息,也就是说不光输入的是上一个层的输出,还多加一个层本身的参数。 RNN有局限有3个 梯度消失和梯度爆炸 有限的上下文 并行化困难
前2个是因为多加的那一层隐藏信息只用一个权重参数表示,信息量有限,而且在重复计算中容易出现崩溃现象 后一个是因为RNN本质是顺序执行的
后来引入了一个新的架构网络长短期记忆(Long shor-Term Memory,LSTM),增加了一个新的状态参数,但也增加了复杂性,也没有能解决并行问题。
新框架Transformer解决上面的问题 Transformer结构通过自注意机制替代循环结构来解决上面的局限性问题,进而实现并行计算和捕捉长期依赖。 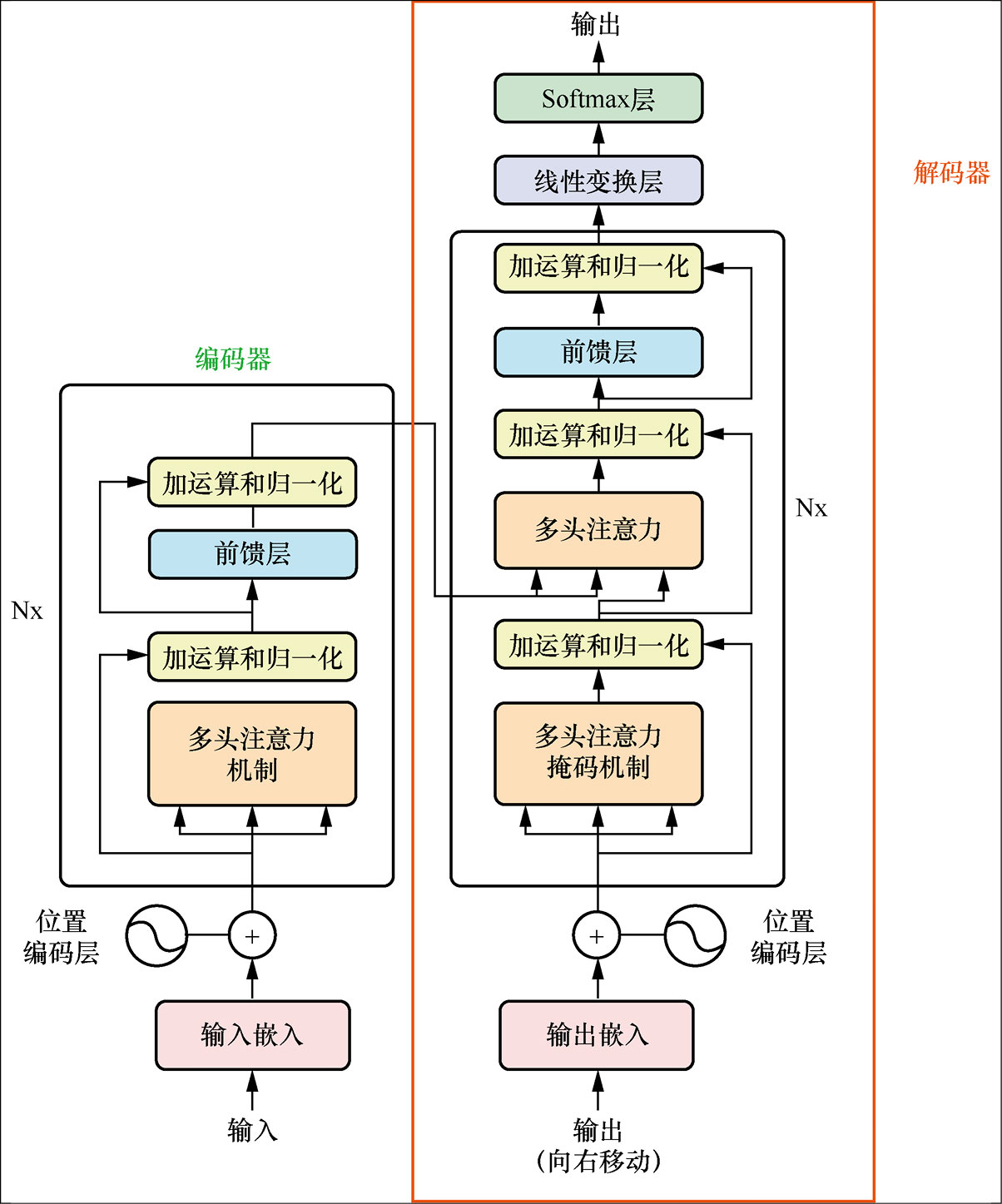 逐一介绍每个部分。
逐一介绍每个部分。
位置编码层:编码器是将自然语言输入转换为数字向量的层。这是通过嵌入过程实现的一种NLP技术,在向量空间中使用向量之间的数学距离表示各向量所代表单词的相似性。
自注意力层:自注意力层负责确定生成输出的每个输入标志的重要性,用于回答“我应该关注输入的哪一部分?”
前馈层:前馈层负责将自注意力层的输出转换为最终输出的适当表示。 前馈层是Transformer体系结构的主要构建块,由以下两个主要元素组成。
- 全连接层(也称为密集层):该层类型中的每个神经元都与前一层每个神经元相连,即来自前一层的每个输入都与当前层中的每个神经元相连,并且当前层中的每个神经元都会影响下一层中的所有神经元的输出。密集层中的每个神经元均通过线性变换计算其输入的加权和。
- 激活函数:这是应用于完全连接层输出的非线性函数。激活函数用于将非线性引入神经元的输出中,也是网络学习输入数据中的复杂模式和关系的必要函数。在GPT中,激活函数是线性整流函数(Rectified Linear Unit,ReLU)。
前馈层的输出随后会被用作网络中下一层的输入。
提示词工程
提示词为什么重要? 提示词可以理解为编程语言中的条件语句,而它在ChatGPT交互中的应用,重要性和编程语言相当。因为它是唯一的控制入口。
自定义OpenAI模型并使其能处理特定任务的一种方法是微调。  微调是一个训练过程,其效果依赖于训练数据集、计算力和训练时间(取决于数据量和计算示例的数量)。
微调是一个训练过程,其效果依赖于训练数据集、计算力和训练时间(取决于数据量和计算示例的数量)。
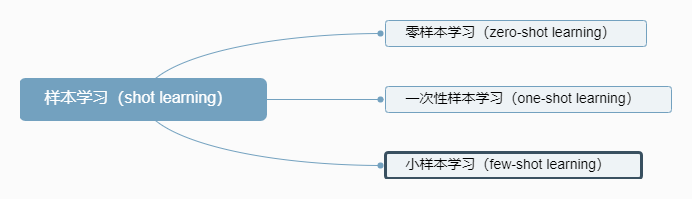 样本学习的学习形式不同于传统的监督学习和微调。样本学习的目标是帮助模型从很少的示例中学习,并由此泛化到新任务。 就是在对话中使用提示词的技巧,让模型变的更有针对性。比如书中,通过在对话中提供大量特定风格的对话样本,让模型产生的对话模仿类似对话风格。
样本学习的学习形式不同于传统的监督学习和微调。样本学习的目标是帮助模型从很少的示例中学习,并由此泛化到新任务。 就是在对话中使用提示词的技巧,让模型变的更有针对性。比如书中,通过在对话中提供大量特定风格的对话样本,让模型产生的对话模仿类似对话风格。 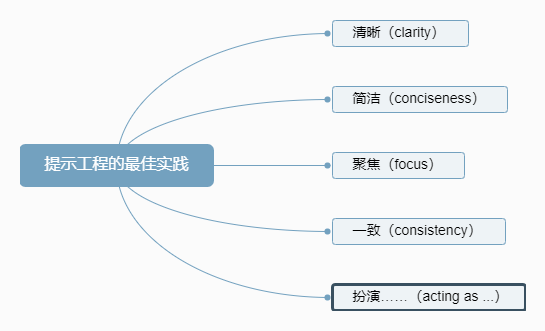 理想的对话:
理想的对话:
- 从简洁、清晰和聚焦的提示开始。
- 确定讨论的相关要素后,即可要求ChatGPT作进一步阐述
- 有时,记住查询的模型和上下文是有用的,尤其是当问题适用于各种域时
- 请牢记前文提到的限制
需要避免的事项:
- 信息过载(information overload):避免向ChatGPT提供过多信息,因为这可能会降低其答复的准确性。
- 开放式问题(open-ended questions):避免向ChatGPT提出模糊的开放式问题。诸如“你能告诉我关于世界的事情吗?”或“你能帮助我参加考试吗?”这样的提示过于宽泛,会导致ChatGPT生成模糊、无用甚至是“幻觉”式的答复。
- 缺乏约束(lack of constraints):如果想让输出以特定的结构呈现,就要向ChatGPT指定结构!
一些新的技术:
- 思维链(Chain-of-Thought,CoT)。将复杂问题分解为较小的,可管理的步骤。
- 主动提示(active-prompt)。从一组查询中选择最重要和有用的问题进行注释,让LLM适用于不同的任务。该方法会使用几个CoT示例查询LLM,并为一组训练问题生成k个可能的答案,然后基于k个答案之间的不一致性计算不确定性度量,即选择最不确定的问题由人类进行注释,最后使用新注释的示例来推理每个问题。
- 原因和行为(Reason and Act,ReAct)。此方法是以人类智能将以任务导向的行为与语言推理无缝结合的能力为基础的。