
当残差开始“失控”:DeepSeek mHC 如何给超连接戴上数学枷锁
按照惯例,DeepSeek会在假期来临时发一篇新论文。
果然,DeepSeek没准备让大家轻松休息,赶着在25年的最后一天发了一篇论文《mHC: Manifold-Constrained Hyper-Connections》(https://arxiv.org/abs/2512.24880), 翻译成中文就是《mHC:流形约束超连接》,这个标题,看起来专业性很强,实际上专业性是很强。但是基于对DeepSeek的期待和信任,我还是得学习一下内容。
好在现在AI能帮助我们学习新知识,把这篇论文导入到Goolge notebook LM中进行学习。
先说论文解决了什么问题
“残差连接”(Residual Connection)的概念
在AI的训练过程中,有一个概念叫“残差连接”(Residual Connection),简单理解,就是在AI的训练时,会对每一个字进行多层次数学运算。比如第1层算出了向量,然后第2层会在的基础上再运算出,依次迭代。
你可能玩过一种传递动作的游戏,第一个人做一个动作展示给第二个人,第二个人再展示给第三个……一系列转递后,最后的游戏者再现出的动作可能会和原意大相径庭。
上面提到的训练过程也可能会有类似情况,多次迭代的运算会使得原始信息完全变形,关键信息或者丢失或者夸张到变形。用计算机术语来说就是深层神经网络中常见的梯度消失或梯度爆炸问题。
为了解决这个问题,上面根据第1层的向量计算时,并不是直接用算出的结果,而在结果上加一个残差函数F,最简单的F函数就是不经修改的原始值。这样第2层的值就可以用表示。这就是残差连接的概念。
用上面游戏的例子来说,相当于第一个人向第二名游戏者展示动作时,还给后者一个纸条,上面写着第一个游戏理解的动作要点,比如“这是一个手部动作,脚不要动”,以提醒第二名游戏者。然后第二名游戏者向第三名游戏者展示动作时,可能会写上他认为的要点来提示“左手抬起,右手摆动”之类。
HC是残差连接的一种优化实现
2024年,字节跳动团队提出了超连接(Hyper-Connections)的实现算法(https://arxiv.org/abs/2409.19606) ,优化了残差连接。
它通过引入可学习的矩阵来调制不同深度特征的连接强度,有效地将残差流从单通道扩展为多通道交互模式。传统的残差连接是简单的相加,而HC则引入了多个矩阵,允许模型在不同深度的残差流之间进行复杂的特征混合和调节。
按上面的游戏来类比,相当于每个人可以传递多个纸条,每个纸条从不同的角度附加上注意事项。
HC优化的好处是,在几乎不增加计算量的前提下提升了性能,但缺点是破坏了稳定性。
这有点反直觉,看起来难道不是增加了计算量,增加了稳定性吗?
这其实要从大模型工程的特殊语境下去理解了。传统的神经网络计算,我们要增加规模时,往往是增加迭代的次数或者增加参数量,也就是从深度和宽度上进行拓展。而HC可以在不变化深度和宽度的前提下,只是在同一次运算时增加一些计算量而已,这些计算量的增加从数学角度量是挺大,但在工程领域,对计算机来说,完全可以忽略不计。
同样,从直觉上,你认为保留前一层的信息越多,稳定性越好,但是事实上,“无约束”的变换恰恰是动荡的源头。标准的残差函数中,只有一个变量,这保证了信号无论传递多少层,既不爆炸也不消失。而HC中,映射矩阵是完全由模型自己学习的,因为没有约束,所以信号量在经过多次迭代后可能指数级放大,会直接导致训练时的梯度爆炸、损失函数突增(Loss Surge)和不收敛
当前HC的计算量增加相对于性能来说可以忽略,但是系统开销的增加是实实在在。原来只要记一个值,现在要记多个矩阵,显存什么的就显著上升了。
mHC是对HC的优化实现
mHC是DeepSeek对HC的优化和改进,为了解决HC不稳定的问题,DeepSeek提出了一个数学解决方案。将 HC 中无约束的可学习空间投影到特定的流形上。就是用Sinkhorn-Knopp 算法将HC中每层需要传递的残差映射矩阵投影到由一个双随机矩阵构成的Birkhoff多面体上。
这里有一些数学术语,其实如果不考虑公式,只用白话来描述,也不是很难理解。
比如说,双随机矩阵就是指一个矩阵中每个元素都是正数,同时,每行所有元素加起来等于1,每列所有元素加起来也是等于1。这样的矩阵就叫双随机矩阵。
所有的双随机矩阵的集合就是所谓的Birkhoff 多面体。
而这个Sinkhorn-Knopp 算法就是把一个矩阵转换成双随机矩阵的算法。可以打个比方,你有一个矩阵,里面的数字是随机的。你先对第1行做一个归一化处理,就是把第1行的各个数映射空间中,只要保证第1行各元素各等于1即可。然后根据这个算法,将矩阵中各元素处理一遍,这样至少第1行是符合要求的,而其它各行各列可能达不到要求。没关系,继续处理第2行,一直到各行都达到要求了,然后再来处理各行,就这样不停地尝试调整。mHC在实际实验中,一般在迭代20次左右会得到一个近似的结果。
还是按上面游戏的例子来说,HC允许上游戏者传递多个纸条,比如4个字条,纸条的内容由上个游戏者自己决定。而mHC呢,只是规定,上个游戏者是可以传多个纸条,但每个纸条的内容不能完全自由发挥,而是要指定性质,比如第一个纸条只能写手的动作。第二个纸条只能脚的动作。第三个纸条只能写脸部的动作,第四个纸条只能写要表达的情绪。
总结一下,残差函数保证了神经网络在运算时保留原始信息,用一个一维数组记录,而HC则将残差函数的能力扩展,保留更多维度的原始信息,用一个2维矩阵记录。而mHC则将这个2维的矩阵变得规范化了。而规范化后矩阵会极大地减少多次传递后梯度爆炸现象。 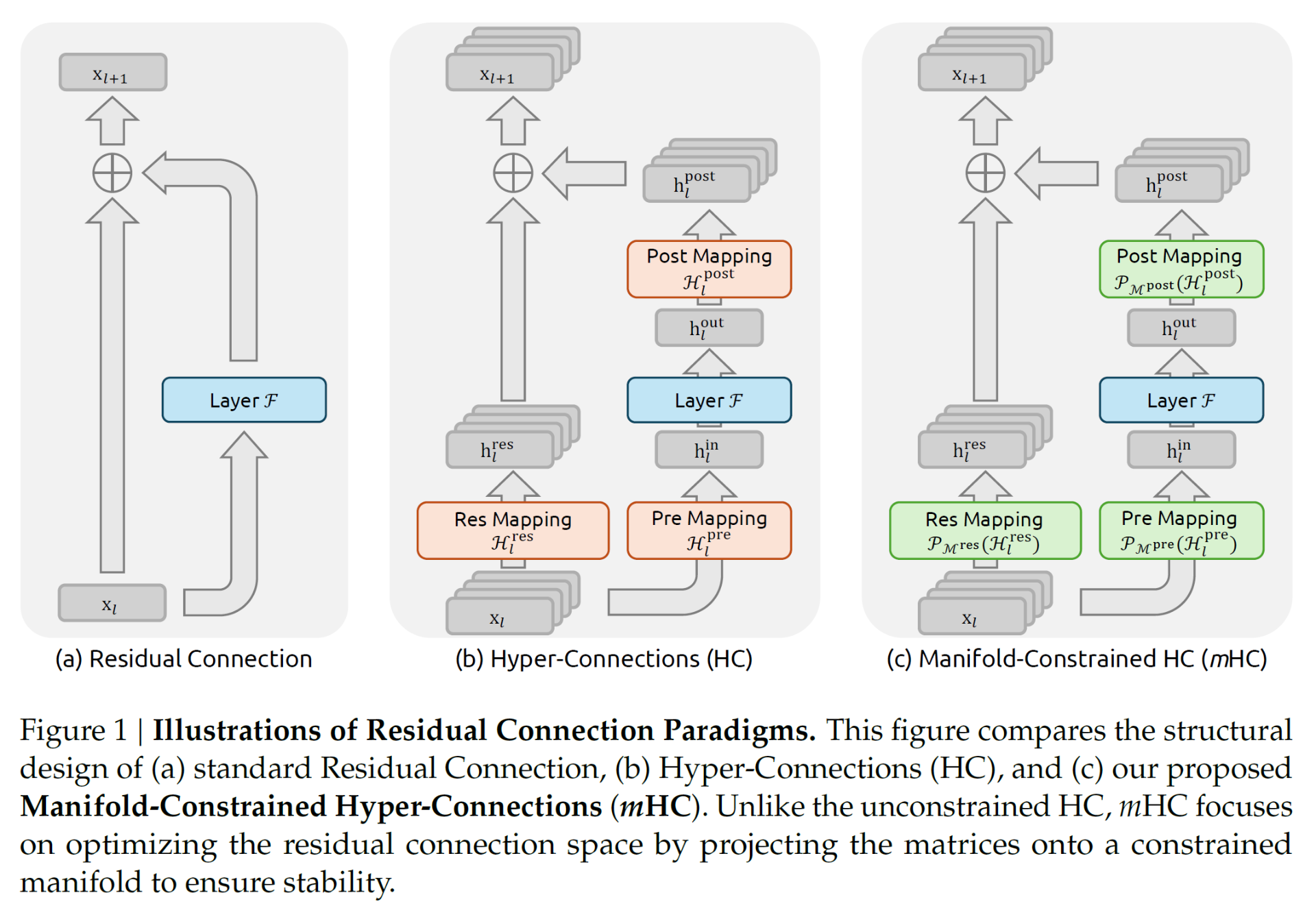
更多技巧性的实践
数学问题解决了,mHC这篇论文还提供了一系列工程学技巧。不光告诉你理论还手把手地告诉你技巧。这个源开的,真是良心啊。
因为残差流的扩展(从一维的向量变成了二维的矩阵),自然带来了巨大的显存和I/O压力。为了减少系统开销,论文中提到三个工程化的手段:
1. 内核融合(Kernel Fusion)
这个是什么意思呢?前面我们提到mHC的哪个Sinkhorn-Knopp 算法,涉及到多个操作,又是归一化,又是矩阵乘法,还有多次迭代等。mHC在代码层次,将这些操作融合进统一的计算内核,这样大大减少了内存的读写次数,减少了显存带宽瓶颈。
这些其实就是对标准算法的一些技巧性改进,比如矩阵归一代时,先将矩阵中各行元素按行依次拼成一个长行,相当于变成一个长的一维向量,然后运算时就减少了迭代次数等。这就是算法常见的用空间换时间策略。
论文中还提到多个内核融合的技巧,本质就是努力在低配置硬件的前提下提升计算效率。
2.选择性重算(Selective Recomputing)
一般来说算好一步后,中间值留在内存中,以后再用时,直接调用即可。但是天可怜见,DeepSeek买不到最新的硬件,只能尽可能在螺蛳壳里做道场。
对于一些占内存大,而计算量不大的数据,模型直接丢弃中间结果,只是在需要时重新计算。
当然,论文中对于哪些内容重算,重算多少,有一个数学模型。但这对于我们来说过于枯燥了。这里就不研究了。
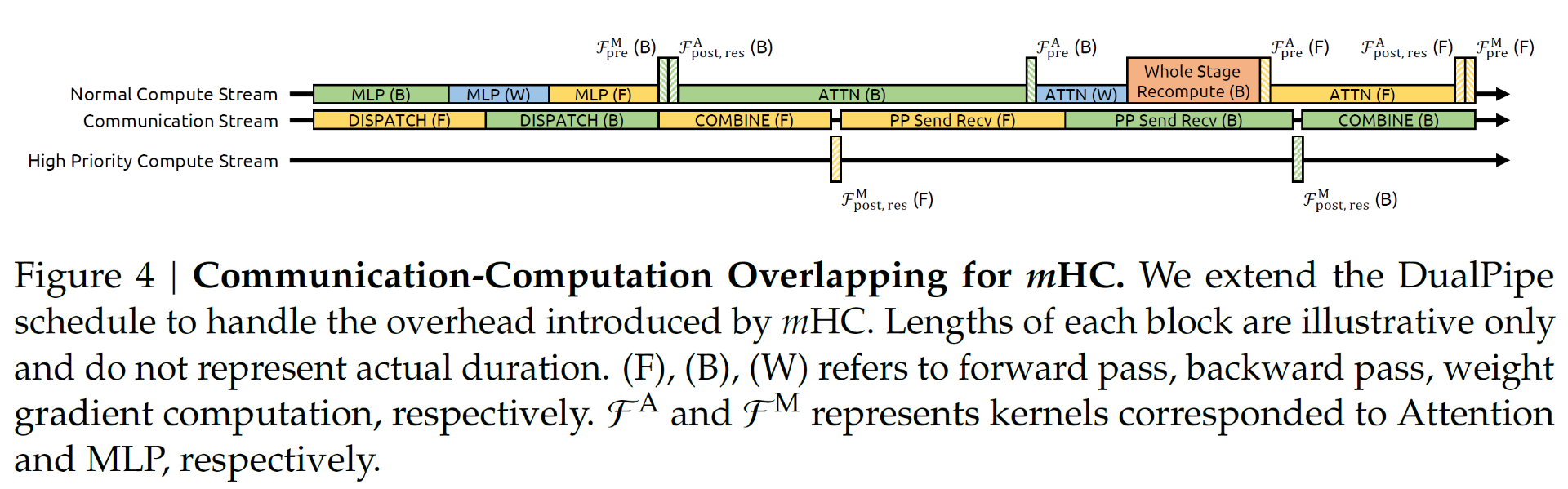
3.通信重叠(Overlapping)
大模型在分布式训练时,肯定会涉及到各个GPU之间的数据通信。DeepSeek使用 DualPipe 调度,优化通信与计算的重叠,解决 I/O 延迟问题。
这里DualPipe调度策略源自DeepSeek-V3,当时主要是为了解决多专家并行和流水线并行的通信与计算重叠。mHC进一步扩展了这一调度方案,创新点在于它建立了一个专用高优先级的计算流(High-Priority Compute Stream),这样防止了计算任务阻塞通信流,确保数据传输能及时启动。
结合上面的重算机制,将重算与通信解耦,重新时不需要等待跨阶段的通信数据。
用比喻来理解,就是原来两个GPU,一个计算过程可能是A先算,结果传给B,确认B得到数据后,A再继续下一步,然后B再根据得到数据运算。现在则是开一个持续的进程,这个进程专门传送中间数据,A在运算完后,直接把数据打个包,标上接收者是B,然后向这个进程一丢就不管了,直接进行下一步,而B则在这个进程中看看有没有给自己的数据,发现了给自己的数据,谁给的就为谁计算。这样就减少了进程的阻塞。
mHC的表现
根据论文中的实验部分,mHC相对于HC的优化主要集中在“更稳”、“更聪明”和“更高效”三个方面。
训练更稳:解决了梯度爆炸问题
在 27B 参数量级的大规模训练实验中,HC 表现出了明显的不稳定性。由于它的连接没有数学约束,信号在多层传递后会像回声一样被无限放大,导致在训练到约 1.2 万步时出现损失函数激增(Loss Surge) 和梯度异常。
mHC 的改进: 它给这些连接带上了双随机约束,强制要求信号在传递时能量守恒。实验显示,mHC 的训练曲线非常平滑,信号放大倍数从 HC 的 3000 倍降低到了极其平稳的 1.6 倍,彻底解决了梯度爆炸的问题。
表现更聪明:逻辑推理能力更强
在 8 项主流测试中,mHC 几乎全面超越了 HC。特别是在需要“烧脑”的逻辑推理任务上提升最明显,例如在 BBH 测试中比 HC 提升了 2.1%,在 DROP 阅读理解测试中提升了 2.3%。这说明约束后的连接虽然“守规矩”,但反而更有效地融合了特征信息。
运行更高效:显存占用小
在残差流扩展了 4 倍的情况下,mHC 带来的额外时间开销仅为 6.7%,这使得大规模训练在工程上变得真正可行且高效。
结语
mHC其实是一个工程优化的方案,我认为谈不上什么革命性。尤其是有些优化,看起来是如此地令人心酸。比如上面三个技巧性的实践,本质是上在低配置硬件条件下的挖潜革新。
美国人限制了最新硬件,DeepSeek只能和华为合作,以数量换质量,所以他要潜心研究分布式运算的通信问题,需要研究充分利用每一字节的内存。
也许正因为精力都放在这些工程细节上,所以最新V4、R2一直迟迟没有发布。但我相信一定会有一个DeepSeek 2.0时刻。