
知识的影子与本体:AI 正在寻找穿透文字的路
自从 2022 年 ChatGPT 3.5 横空出世,让世人领略到 AI 的非凡魅力;再到 2024 年底 DeepSeek 惊艳登场,给国人带来了巨大的惊喜与自信。如今,各类大模型(LLM)及 AI 应用已经深刻地改变了我们的生活。
AI 每天都在增强功能。昨天做不到的事,今天已经能做;前天做不好的题,今天已经可以轻松解决。我们仿佛回到了蒸汽机投入实用后的那段时间——新技术、新发明以肉眼可见的速度狂飙突进。
然而,在这波 AI 浪潮的狂欢背后,科技界仍存争议:LLM 真的是通往 AGI(通用人工智能)的正确方向吗? 或者说,仅靠当前的 LLM 就足够了吗?
答案其实很清晰:不够。
Transformer 是一次伟大的突破,但要让机器真正“理解世界”,我们仍需要更多类似 Transformer 等级的全新核心技术。
冻结的知识快照不是智能
我们知道,当前大模型的训练方法,本质是让 Transformer 在大量文本里寻找“词与词的关系”,并基于这些统计关系预测下一个词。
训练完成后,所有知识都被压缩进最终的权重文件里,像一张凝固的“知识快照”。 但之后它不会自动学习新知识,除非重新训练或微调。明天产生的新知识无法自动融入,换言之,LLM 本身没有实时的学习能力。
从上面你很快能就发现当前基于LLM的AI的两个“死穴”:
其一,LLM只是一个概率模型,它知道“E=mc²”后面大概率跟着“爱因斯坦”,也知道怎么用这句话造句,但它不知道这公式是怎么推导出来的,也不知道如果光速改变了世界会怎样。它学到的是知识的“投影”(文字),而不是知识的“本体”(逻辑与因果)。
其二,它的知识是静态的。正因为它没有一个知识的生产过程,所以它不知道这些知识是如何产生的,为什么会形成这个知识,这些知识为什么对,为什么错。
正如X上有某位大佬所言:“当前 AI 水平离真正的 AGI 还差好几个 Transformer 级别的创新。” 但遗憾的是,现在还没有可以取代Transformer的新架构。
在这一点上,中美其实“站在同一片荒原上”,未来怎么走,大家都在摸索。
理解知识的积累过程,是智能的前提吗?
回想一下人类的学习方式:从小到大,知识是一点一滴积累的,对同一个知识点的理解也是层层递进的。相比之下,LLM 生成即“冻结”,缺失了进化的过程,所以它“知道”,但它不“理解”。
那么,将知识的积累过程保留下来,会不会是通往 AGI 的一个方向?
如果 AI 能复现人类对某个现象的认识过程,是否就能理解其背后的原理,从而举一反三?至少,可以将这个认识过程当作一种“元模式”记录下来,在处理新问题时按部就班地套用。
当然,这个观点也存在争议。因为许多科学突破是“断层式”的——先是天才的“灵光一闪”,后人再通过逻辑去填补证据。
不过,从人类的普适经验来看,模拟知识的积累过程,肯定有助于 AI 达到人类智能的平均水准。我们不指望 AI 顿悟成爱因斯坦,但达到专家的水平是完全可期的。
这个过程可以从两个角度来分析
一是知识的层级性,高阶知识依赖并建立在前导知识(基础概念、技能)之上。比如说,一个人学习流体力学前,需掌握微积分与线性代数。
二是学习的渐进性,对具体知识的理解和记忆,是一个从模糊、具体到清晰、抽象的动态过程。对于个人来说,对新概念的掌握,会从最初的生硬记忆,逐渐内化为可灵活运用的直觉。
Google的思考:结构化与记忆
针对第一个维度(层级性),Google 试图将模型的知识结构化为不同时间尺度、相互嵌套的层级,提出了**“嵌套学习”(Nested Learning)与记忆框架。(参见论文:https://abehrouz.github.io/files/NL.pdf)。
“嵌套学习”的核心是将一个复杂的AI模型,视为一系列相互嵌套的优化问题。简单来说,模型的不同部分可以像人的不同记忆一样,以不同的“速度”学习和更新。
简单举例,一般的LLM训练,对于一个文本来说,可以理解成一个平面,从上而下,流式分布。然后训练过程相当于找出每个字之间的关系概率,因为处理窗口的关系,如果算到了后面的内容,往往与前面的文字关系就小了,计算时用的权重也就低了。如同一篇小说,即使作者费尽心机在结尾时回应了开头处的一个梗,填了开始的一个坑,对于AI来说,也是抛媚眼给瞎子看。AI早就忘记了。
而Google的嵌套学习,则是对同一篇文章,除正常的训练方式外,还对文章先在不同的层次上进行预处理。比如先做一个文章梗概,先过一遍文章,把所有作者预埋的“坑”提取出来……,这样一篇文本就变成了n篇不同维度文本,然后在训练时,这些文本都参与训练,可以并行处理,只是训练参数和训练方法不同。能根据性质选择不同精度和速度的计算,而且训练出的成果是可以叠加的,不再是单一固定的权重文件。
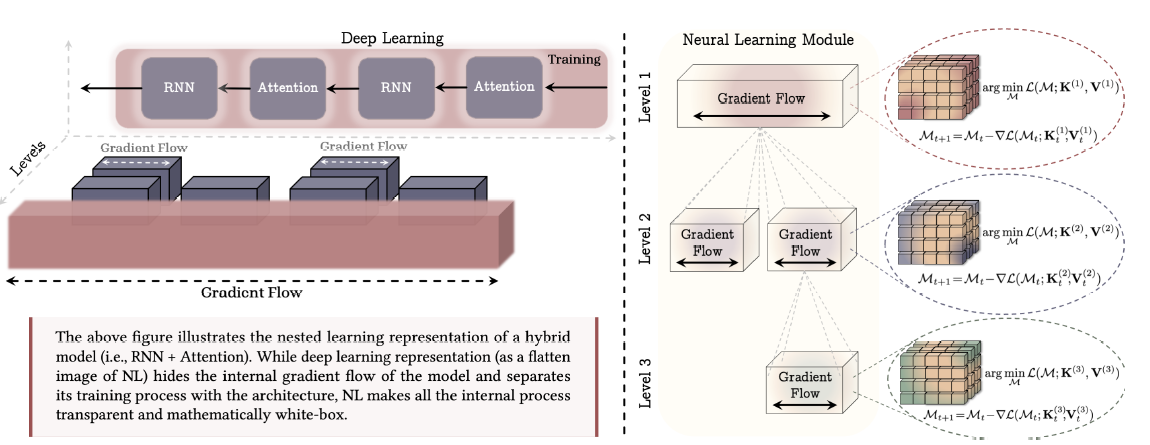
上面的图就是一个例子,左边是普通的深度学习训练过程,而右边则是嵌套学习的例子,你能看出对于同一个内容,根据进行多次训练,只是广度和精度各不相同。
此外,Google 的 ReasoningBank 记忆框架(相关论文:https://arxiv.org/abs/2509.25140 )则更进一步。它的思路是让AI智能体从以往的成功与失败经验中,主动提炼出结构化的“记忆项”。每个“记忆项”包含策略标题、描述和推理内容,本质上是对低级经验的抽象总结。当面对新任务时,AI会检索并应用这些抽象原则来指导行动,这模拟了人类专家运用已有知识框架去解决新问题的过程。
DeepSeek的尝试:多维感知与自验证推理
针对第二个维度(渐进性),DeepSeek 在感知与推理两个层面都展现了对人类思维模式的深度模拟。
首先在视觉感知层面,以 DeepSeek-OCR 为例,他们采用了一种独特的“多分辨率训练”思路:不仅仅是对图像进行简单的向量化,而是试图模拟人类的视觉认知过程——即 “从模糊到清晰” 的动态扫描。对同一张图片(场景),模型会同时学习其低分辨率的宏观轮廓与高分辨率的微观细节(相关技术细节可参看此前的公众号文章)。这种策略暗合了人类大脑处理视觉信息的生物学模式:先建立全局印象,再填充局部细节。
不仅在感知上发力,DeepSeek 更试图在推理层面重现人类的“反思”能力。
DeepSeek 不仅在基础大模型上发力,向各个专家模型演进(如 DeepSeekMath-V2),更在某些领域尝试模拟人类的“记忆状态”。
在 2025 年 11 月 27 日刚刚发布的 DeepSeekMath-V2(论文:https://arxiv.org/pdf/2511.22570 )中,DeepSeek 引入了突破性的 “自验证”(Self-Verification) 机制。
这相当于让 AI 进化出了“自我监考”的能力。传统的模型像是一个只顾填答题卡的考生,只在乎最终答案是否命中;而 DeepSeekMath-V2 则像是一个严格的老师,它不仅检查答案的对错,更会一步步审视 解题过程(Process) 的逻辑链条。通过这种方式,模型不再是“蒙”对了一个答案,而是真正确信自己“理解”了这道题。这种从“结果导向”向“过程导向”的转变,是 AI 迈向深度逻辑推理的关键一步。
DeepSeek 的“自验证”机制构成了一个自我完善的智能闭环:它不仅能评估解题过程,更能主动生成推理步骤并对其验证。这模仿了人类的元认知与自我学习能力。古人倡导“吾日三省吾身”,而 AI 则可实现瞬时、高频的自我审视与迭代优化。如下图(论文中的附图)所示,随着验证次数(最高达7次)的增加,模型解决问题的能力显著提升,充分体现了通过“反复自学”实现能力进化的潜力。
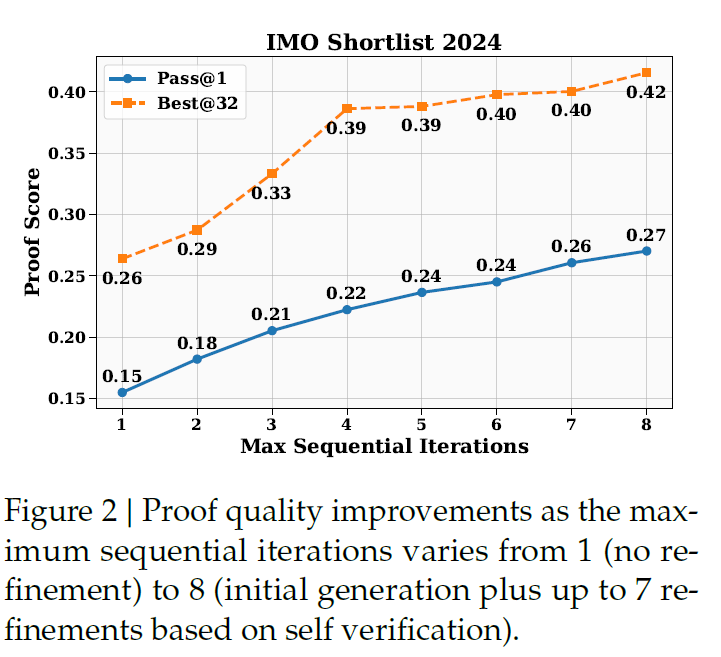
虽然上述分别列举了两家公司的例子,但在技术演进的洪流中,它们并非孤立存在。Google 的嵌套学习涉及不同清晰度数据的处理,而 DeepSeek 的多专家系统(MoE)及多层次数据训练,本质上也是在对知识进行结构化拆解。
结尾:AGI的未来方向,也许正在悄悄显现
从 Google 到 DeepSeek,我们正在看到一个趋势越来越明确:
真正的智能,不是更大的模型,而是更“结构化”的学习过程。
未来的 AI,可能会具备:
- 能分层理解知识结构的能力
- 能保持多时间尺度记忆的能力
- 能自主总结“经验规则”的能力
- 能在模糊与清晰之间渐进切换的能力
- 能记录“知识的进化史”而不是只记录结论
这些能力加在一起,不是“下一代更大的 Transformer”,而是:一种能够像人一样“成长”的架构。
我们或许距离 AGI 仍有数个重要突破,但路径正在变得越来越清晰:不是简单堆算力、堆数据,而是让模型获得“理解知识如何生成”的能力。
或许,真正的智能不是一夜之间的奇迹,而是一次又一次让机器“重走人类认知之路”的漫长积累。而现在,我们正在走在这条路的最前面。