
愚人成大事:从AI的过拟合到决策的混沌智慧
愚人成大事:从AI的过拟合到决策的混沌智慧
保持饥饿,保持愚蠢。——乔布斯

如果你仔细观察这个世界,就会发现一些奇怪的现状:最“草台”的制度,反而撑起了最庞大的机器;最“愚蠢”的政策,常常带来最深远的影响。古今中外,莫不如此。
比如,当年美国基于清教徒的传统搞了一个禁酒令,原本是想让大家清心寡欲,让大家过着让上帝满意的“符合道德”的人生。
结果黑帮横行、私酒泛滥、夜总会开满大街。但也正是因为这场“史上最失败的道德工程”,美国的娱乐业、执法系统、以及对公共政策的反思体系被硬生生拉升了一个维度。
再比如,2016年印度的莫迪老仙突然宣布“废钞”——在乱哄哄的争执中,几亿人突然发现口袋中的纸币变成了废纸,当年我抱着乐子人的心态看的眼花缭乱。但事后,却意外令移动支付在印度农村指数级爆发,间接带动了金融普惠。
还有中国58年的“全民大炼钢铁”,其科学上的荒谬性毋庸置疑,在经济上损失巨大。但是从长期来看,却推动了工业概念在农村基层的传播,某种意义上,它为后来的乡镇企业播下了“人民也能搞工业”的种子。
这些故事的共同点在于:它们在逻辑上说不通,但在历史上说得通。这些决策是错的吗?当然是,因为它们不符合人性,不符合规律,不符合科学。造成的损失也是很直观的,但是从更高的维度,愚蠢的决策却能形成一些意外结果。
也许,这就是“决策的混沌智慧”:一个系统的前进,有时靠的不是全知全能的冷静计算,而是模糊、感性、甚至带点荒唐的集体冲动。
01 机器学习教你做事
现在的人工智能,基础在于机器学习,通过算法发现人类知识的规律,获得智能。好比小孩子从课本学习知识。你的第一反应肯定是,教给机器的知识越多越好,越细越好,越准确越好。
在人工智能的发展早期的确如此。这也是大数据理论的由来。就拿ChatGPT为例,为什么一直到3.0版本时才表现出可用的智能度呢?因为只有在这个版本时输入的数据量才足够多,才会出现“涌现”现象。尽管没有公开,但仅从其输出参数量达到了1750亿个,就可以想象参与训练的数据有多庞大。
但是科学家们很快发现,过度训练(如GPT-3的8B版本训练量达必要量的100倍)反而会加速数据消耗且无益于性能提升。这说明突破阈值后的过量数据输入属于资源浪费。
经常做量化训练的朋友都知道,自己训练出来的模型是如此完美,回测时收益率可达200%,但一实操却赔得只剩下裤衩。不懂量化的学者可能只是在旁边撇了撇嘴:“过拟合”。
用通俗的语言来解释过拟合就是,你在学习过程中完美地复刻了数据,学到了许多不必要的细节,而在真实的世界里,有许多的细节是随机的错误。就拿量化来举例,有些涨跌是随机或者偶然的错误,可能仅仅是交易员打翻了水杯,误下了一笔大单引起暴跌,你一定要找到这次下跌的原因,很可能就适得其反了。机器学习的基础是数据,比如一个分类算法,要求你从下列点中找到一个模型,能将橙色的点和绿色的叉分类, 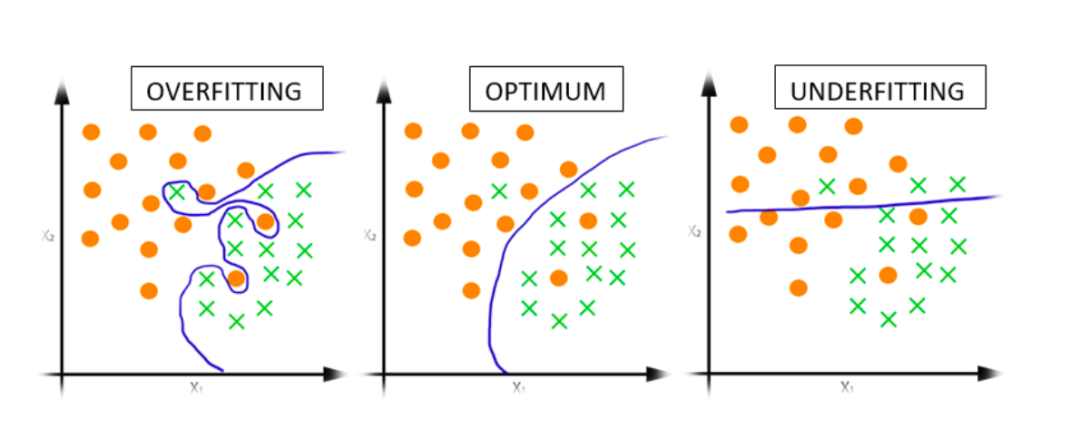
第一个图,找到一个复杂的方程来表达蓝色的曲线,能完美地在这些点中找到所有的数据,这就是拟合了,因为你用这个方程在对一个新出现的点进行分类时,十有八九是错的。上面只有中间的结果才是最优解,尽管在现有数据中都有3个点的判断是错误的。而右图,我们称之为“欠拟合”。
为什么会这样呢?这是因为现实中有大量无关、冗余甚至错误的信息,我们称之为“噪声”,这些噪声会掩盖真正有价值的信号。即使信息都是正确的,过多的信息也会让信息的维度呈几何级数增加,让计算因为过载而出现错误。用学术点的话来描述就是:“过拟合”会让模型失去“泛化”能力。
因为人脑比机器更不擅长于处理海量信息,因为人脑在亿万年的进化中,发展出的生存策略其实是“偷懒”,核心在于模式识别与信息简化。你看一看天说“要下雨了”,可能是经验,或者是直觉,并不会先收集温度值、温度值,风速风向,然后再代入一个公式……,意识的注意力资源是极其有限的。
所以机器学习教我们的是:决策前要收集信息,但更重要是的要有判断力,不要被信息淹没,因为你没有足够的能力来处理这些信息。我们说一个人的直觉判断,其实是指这个人依靠大脑的本能,将信息进行了维度压缩,这种压缩依赖你的智力,也依赖你的经验。这种判断不准,但是够用,不精确,但足以推动你行动。
02 草台班子的决策更有效
我们常常听到一种说法“世界是个巨大的草台班子”,现实中的各种新闻、让你看到精英们的各种骚操作,你不是有一种“彼可取而代之”的责任感?这还真可能是你想多了。
首先,我们可以想象两个领导者要组建他们的班底,一个是完美型,他在组建新先制定好严密的团队目标,预定好完备的组织结构,每个岗位职责明确,每个成员精心挑选,个个责任心和能力都足够,又都放在适当的岗位上。另一个是草台型,他创建的组织流程混乱、分工含糊,人员松散。
很明显,从能力来看,前者远大于后者,如果所有的前提条件一致,前者的决策肯定是表现完美。现实中的情况往往并非如此。其实从两位领导者组建团队的方式开始,就已经决定了两类领导者不同的性格和决策方式,而这两类方式,也决定了他们两者获取信息的方式和使用信息的差异。
现实中的信息是模糊的,如果你需要一个精密运行的流程中产出正确的决策,需要信息是精准的,一是需要正确二是需要适当,不足或过量都不好。正如我们在前面提到的机器学习算法,数据不足和数据过多都会引发性能的劣化。机器学习过程是可以重复进行的,可以通过无数次的尝试寻找恰当的参数,但在社会现实中,决策是需要在很短的时间完成,而且没有对照组,根本没有试错的机会。
现实中的决策是一个决策链,它往往由多个节点组成,正因为每个节点的信息都是模糊的,类比于统计学中“误差相互抵销”原理,这些节点的误差可以相互抵销,这时如果有一个节点的数据特别准确,反而会打破平衡,让系统的表现更差。
最后一点就是,草台班子更容易仓促地作出决策,而很多事情的关键并不在于对错,而在于快慢。深思熟虑作出的决定可能很好,但是更可能的情况是错失良机。比如量化交易中最赚钱的流派其实就是高频交易。
我们在回顾过去的案例时,其实很少能看到精心策划的计划,更多的是在信息模糊、时间紧迫、资源有限、利益复杂的约束下,演化出的适应性策略。
我们说草台班子的决策更有效,其实说是一个现实,而不是在说它的合理性。这种反直觉的现象其实是人脑的一个缺陷。正常人类面对现代社会复杂的信息流,其实是处理不过来的。我们常常能从各种名人传记中看到他们决策时的“直觉”,其实正说明了有效的决策需要舍弃精确性,选择战略性模糊。
03 复杂系统的混沌协作
也许你最终能接受这个草台班子主导的世界,但你一定会好奇,如果草台班子恰好碰对了一个正确的决策,得到好的结果自是可以理解的,但为什么有一些明显很愚蠢的决策仍能正常地运作?
这需要从头说过,首先我们思考一个问题:即使象铅笔这样简单的产品都涉及到成千上万不同行业人的合作,那么人们是如何在没有任何人能完整理解一个产品所有细节的同时组织类似于生产芯片、组织登月等复杂项目的?
现代社会进化到当前阶段,历史上那种全知全才已经不存在了,现代所有的项目都依赖于组织结构的保障、模块化分工体系的运作、标准化协议支持、分层抽象的知识管理、容错与冗余的设计、信任体系的构建。
这也正是因为人脑的局限,没有人能掌握全部知识,迫使人类发展出这套协作体系。这样不管什么样的决策,最终都是要投入这套体系来执行。
这套人类协作体系,其实正表现出草台班子的某些特性:结构松散、职责交叉、人员能力参差。在运作过程中更多地表现出一个混沌的黑箱状态。而这套混沌协作的黑箱体系,又恰好达到了一个容错设计和动态纠偏的效果。
我想每个领导者,都会抱怨下属的执行力吧?这其实人类社会的正常状态,因为人类社会就是这么运行的。
再完美的方案,投入这个系统,执行效果肯定会有缺憾。再愚蠢的政策,在执行过程都会有优化。
而这套运作体系的进化,个人是无能为力的,我们不知道它是如何形成的,也不知道应该如何促进其进化,不过前面机器学习给过我们启示,也许我们也可以参考机器学习的方法来理解这套体系的进化过程,就是对每个项目完成的结果进行评估,然后通过激励和惩罚机制来淘汰部分节点。但是理解这些好像也无助于加速进化的速度。 
04 拥抱必要的愚蠢
好吧,既然这世界的真相就是如此,我们不得不接受草台班子,因为只有他们能做出有用的决策。或者说,只有他们才能做出决策。坏决定总好过不行动。这样来看,草台班子其实是人类文明进化机制的一部分,我们之所以能进步,不是因为我们总是做出正确的决定,而是在因为我们能在混乱中逐步改进,在局限中不停重构组织,在失败中学习经验。
再说了,我们也不必如此自负,总是以“肉食者鄙”的心态来看待领导者。你以为的草台班子未必是因为领导者蠢,可能正是因为你自己的愚蠢。毕竟领导们的主要责职是驱动其它人行动,统治者的功能主要是协调,他们要做的事是带领我们前进。一个聪明人要带领一群傻子前进,最好的办法是扮演傻子才能和我们融为一体,才能让我们心甘情愿地追随。
而且从群体心理学上来说,有时愚蠢的政策反而能激活集体的参与,比如用简单的口号动员大众。
总之,我们得保持足够的谦卑,要理解草台班子的决策过程,在批评愚蠢命令时要理解政策发布的背景执行过程中动态的反馈。同样,我们自己在决策时,也要明白信息的取舍,并保持决策的弹性和容错性。
05 结语:糊涂不是问题,装聪明才是
我们从机器学习的过拟合现象发现精准不是智慧,反而可能是错误的陷阱。
我们观察草台班子的决策过程和执行过程,意识到“乱中有序”的混沌协作机制是人类处理复杂问题的本质。
然后我们不得不承认,看似草台的班子也许深谙人性本质。
正是因为人类文明不是靠聪明人的明智决策,而是靠普通人的低效合作才能进步的。我们才能认识到糊涂不是问题,真正危险的是装聪明的人。我们要做的是,成为那个看起来糊涂,但总能推动事情向前的人。
2025-06-08