
人类灭绝后,AI会统治地球吗?
人类灭绝后,AI会统治地球吗?
“ 如果明天人类突然灭绝,人类创造的AI能否继承人类的遗产,进化成地球的主人?”
 这个脑洞的关键在于,AI能否在没有人类帮助的情况下理解这个世界。AI有没有从事物的表像中发现内在的规律的能力。
这个脑洞的关键在于,AI能否在没有人类帮助的情况下理解这个世界。AI有没有从事物的表像中发现内在的规律的能力。 
01 不会做梦的仿生人
“如果它看起来像鸭子,走起路来像鸭子,并且叫声也像鸭子,那么它可能是一只机器鸭子。” 
如今如火如荼的AI技术,可以分成两类
一类如ChatGPT、DeepSeek之类的大语言模型。它们的原理是从现存人类的文字中寻找规律。本质上是猜下一个字的游戏。你和它对话,你以为它是先理解你的问题,然后再去搜索知识库,整理思路,组织语言,最后输出。其实不然,它只是先重复你的问题,然后进行续写,一个字一个字,一个词一个词的续写。它不关心你问题中的情绪,也不在意你问题中的陷阱。和你推动小球,小球滚动一样只符合物理规律。
从实现技术的角度,大语言模型(如GPT系列)主要基于Transformer架构,通过大规模无标注文本数据进行预训练,学习语言的统计规律和语义信息。其训练目标是生成符合语言模式的文本,而非确保事实准确,因为其本质是“概率预测”
另外还有如豆包、Sora、可灵之类的文生图、文生视频的模型。当前可用的模型主要都是使用扩散模型(Diffusion Model),扩散模型是怎么生成图片的呢?想象一下,你有一张画在宣纸上的图片,将它放在水中,你能看到这张图上的各种颜料在水中一点点泅散开,最终变成一团模糊的色块。AI会记下这个过程,把这个过程中每一步颜色点变化数字化,比如这个红色点的浓度1秒后从100变成80,同时四周的点的浓度从0变成35,记下这个变化最接近的一个多项式方程……,这就是训练过程,而生图就变成这个过程的逆过程,从一个完全模糊的色块,对每个像素点一步步复原,最终生成清晰的图片。
除扩散模型,主要还会涉及到技术包括生成对抗网络(GAN)、变分自编码器(VAE)。生成对抗网络(GAN)由两个部分组成,生成器和判断器,生成器负责画图,判断器负责判断这个图是不是达到了标准。生成器通过大量看图学习绘图,判断器通过大量看图学习提高判断标准。通过二者反复的对抗训练生成高质量的图像。VAE则是一种从真实图片中压缩提取核心特征,并理解这些特征的变化范围的算法。比如,VAE可以从海量标注为“微笑”的照片中得到“嘴角上扬15度左右”是其核心特征等。
从上面的说明能看到,所有的一切都是数学。都是一些概率问题。
从中我们可以得到两个关于当前人工智能的现状:
当前可用的AI因为技术路径,分成生文和生图两个类型。 大语言模型主要处理一维文本信息,通过Transformer的自注意力机制捕捉上下文中的长距离依赖关系。而文生图模型则需要处理二维图像信息,或者加上时间维度进行扩展以生成视频。
当前AI的任何智能表现,完成依赖于人类的标注。 如果没有人类对事物的认识和总结,AI就表现不出任何智能。
所以如果明天人类消失,当前的人工智能和其它的人造物一样,很快会湮没在时间的长河中。
02 凡人成神的努力-塑形
女娲抟土造人,最后吹的那口气才是赋予人类灵魂的关键。
如果用人工智能类比,现在只是用粘土做了左右手的模型,离塑人还差得远呢,更不要说什么赋予灵魂了。但不管怎么说,这总是一个良好的开始。
现在左手和右手只能做不同的事情,这可不行,我们又不是只造印度人。
最直接的想法是,用同一个模型来解决生文和生图两种工作。当前DeepSeek和OpenAI也都是这么想的,所以有资料显示,他们都在为统一模型而努力。 
根据上面对算法的简单介绍,我们能总结出“预测是统一的本质”。
- 大语言模型(如DeepSeek、ChatGPT):通过训练大量的文本数据来预测下一个词(token),学到语言的统计模式、逻辑结构、上下文关系。
- 图像/视频生成模型(如GAN、VAE、Diffusion):通过训练预测图像中的像素分布(或其变化),在一定条件下生成逼真的图像或视频。
换句话说:
无论是文本、图像还是视频,本质上,当前的生成模型都是在学习“上下文中的条件概率分布”来进行预测。
这种“预测能力”成为了模型所谓的“智能”的基础。这种能力也正是使得不同模态(语言、图像、视频)可以走向多模态统一(Multimodal Foundation Models) 的关键。
通过对文献的查询,你能发现DeepSeek(Janus-Pro模型)和ChatGPT(ChatGPT-4o模型)都不约而同地走上了相同的道路,他们都是先将不同类型的输入格式统一编码成相同的格式,然后对它进行Transfomer化处理。 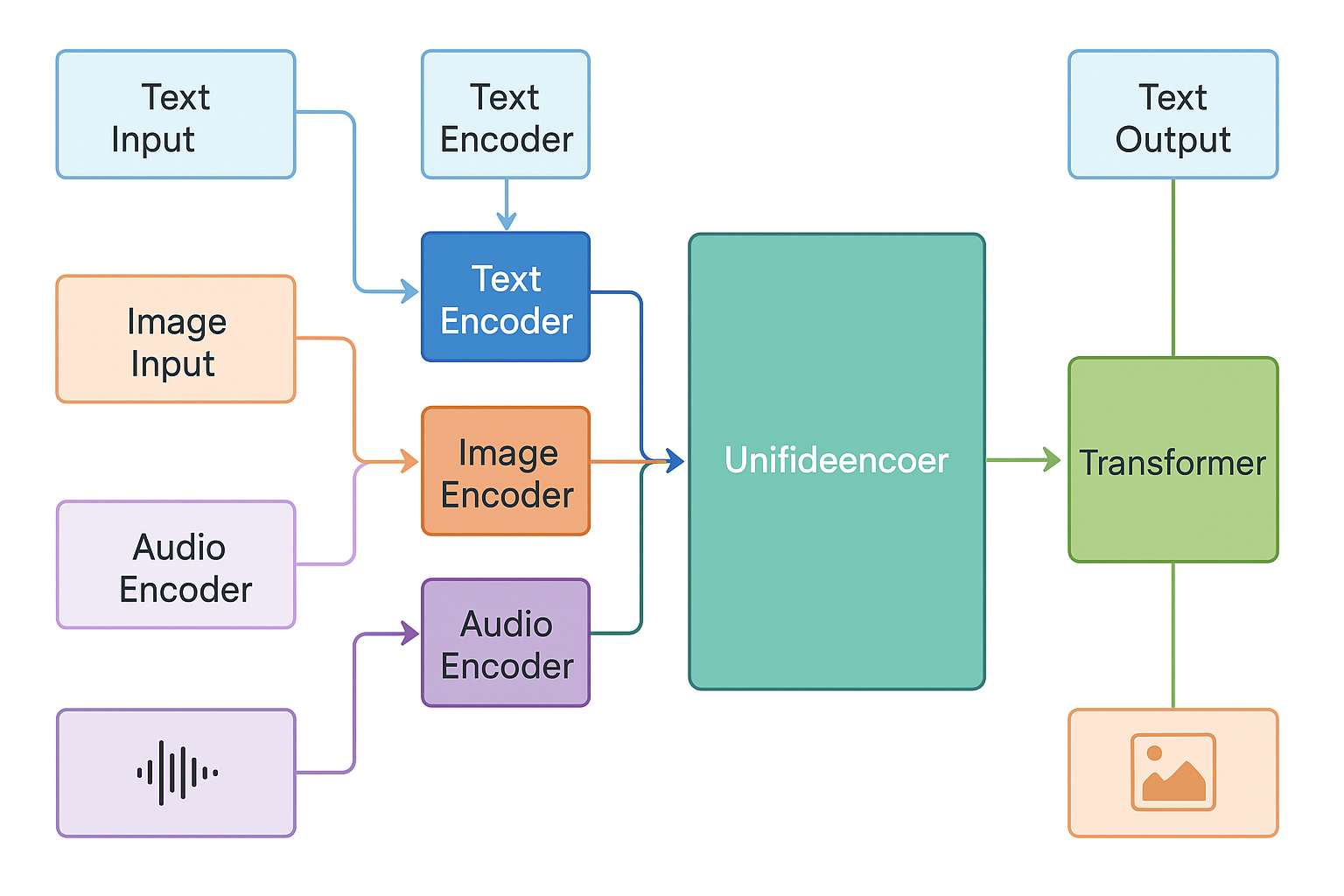
在统一训练素材,统一训练空间的同时,你也许能感觉到AI的这两个擅长方向和人脑有点类似啊,左脑理性处理文本,右脑感性处理图像。但大脑还有一个胼胝体啊,大脑可以靠它将左右脑连在一起共同完成任务。那么我们也可以把前面提到两类模型类比一下啊。 
上图中胼胝体位置的标的“多模态对齐”模块主要涉及Q-Former、Cross-Attention、共享Transformer等技术。
就像人脑中,左脑负责逻辑、右脑处理图像,彼此分工明确,但通过胼胝体连接进行高效协同——AI系统同样可以采用这种“模块分离 + 信息桥接”的方式。通过多模态对齐进行认识同步。
我们也可以打开思路,既然是我们创造人,为什么一定要两只手呢,我可以创造三只手或者多只手,好比千手观音,反正手足够多,完全可以专手专用。画画的手不写字,提桶的手不打脸…… 
实际上,通过可插拔多模块、任务定制的方式更能发挥系统工程的优势,在实际部署中比统一大模型更高效可控。这些技术在现实中各大厂商中的大模型产品中也都有体现。
但是要让AI能独立进化,我们必须让AI有理解这个世界的能力,那么就必须走统一模型的道路。因为只有统一模型才能避免盲人摸象的缺陷。
现在大家对AI都有一种盲目的乐观,其实这一切都仅仅只是开始。
首先我们必须生成了一个有足够“泛化”能力的训练模型,即 “统一模型”,这样AI的上限是能模拟一个人类世界的表征,这时,人类知识的上限就是AI知识的上限。可以用一个“有超忆症的白痴”来类比,他能记住所有的知识,并复述出来。
然后,我们才可能为AI构建一个 “世界模型”,这个“世界模型”是指AI对它知识库内部环境中规律的理解,比如说,AI可以通过观察知识库中成千上万的棋谱,总结理解出下棋的规则。也就是说,世界模型能让AI自主模拟环境状态变化、预测未来,并基于因果关系进行决策。这时,AI可以表现的象一个具体的正常人类,能从现有的知识库中学习,并使用学习到的规律进行测算。
根据现有的技术及发展趋势,世界模型从技术角度是可以实现的。而这些技术对于AI在实现应用中的表现会非常突出。用一个智驾系统为例,现在的智驾行为都是用真实行驶的数据来训练的,因为大多数人在看见大货车后,会自动减速避让,这样AI可能也会选择相同的驾驶行为,但它并不知道这种行为的底层逻辑。一个有世界模型的AI,它因为懂物理定理,它驾驶中,在看到大货车的同时,可能会先在自己的“潜在空间”里,先用获得的各项数据,模拟一个随后可能发生的各种情况的计算,以预测未来可能各种状态,从而决定采用什么驾驶策略。也就是说,它的行为基于因果推理而不是基于历史数据。
但是,因为现实中充满各种不可预测的因果、偶然和干扰,世界模型的构建是非常困难的。
就算我们未来构建出极其强大的世界模型,我们能否说它理解了世界呢?或者说是不可以说AI成了一个有智能的新物种呢?
不能!
因为它只能从人类的知识库中学习。真正的生命还应该有从真实世界中学习的能力。回到标题的中的问题,如果AI已经能据有了世界模型能力,如果人类灭绝,AI应该能继续人类现有的能力,成为一个文明的纪念碑,但这个文明不会进步。
03 凡人成神的努力-赋魂
女娲造人后还有一个赋魂的关键步骤,只有完成了赋魂,人才能成为人。世上所有造人的神话都很类似,在完成了人形后,还需要吹上一口气进行赋魂。
拥有了世界模型的AI,也需要这么一口气。只有被赋魂后的AI才会真正走向生命之路。
我们可以想象一下,人与AI的区别,AI即使因为拥有了世界模型而能预测世界,但它仍不具备“我在理解”或“我有动机”的意识,就是说它没有“自我意识”。因为没有“自我”,所以也就缺乏情境感知,不知道“我在哪”,没有存在性。也因为没有“自我”,自然也缺乏价值系统,没有“信仰”和“意愿”。简而言之,可以用我们常见的“灵魂三问”来概括:我是谁?我在哪里?我要向何处去?
现在的问题是如何走出第一步,让AI产生对“自我”的认知。我们总希望能找到一种技术赋予AI自我意识。因为我们一直默认,人类之所以异于万物是因为人类有灵魂。
但是人类学家们可能会有不同的看法,人类婴儿并不是出生就具备完整的“自我”意识。研究表明,婴儿从出生起,能区分“自我触碰”与“外界触碰”,6个月时能在行为和脑电上表现出对“体周环境”的感知,6~9个月时能意识到“客体”的真实性,9月个后才能通过镜子意识到自我,在18个月后才能表现出“反思型的自我”。
也许我们可以从婴儿自我意识的形成过程得到启发,为了让AI能建立自我意识,
首先得给它一具物理的身体,只有物理的身体才有具身性,可以感知自我的存在,尤其是在面对镜像实验时。只有有了物理的身体,才能通过在真实环境中的各种限制和反馈,感知到自身的存在。这么看来,无论是从哲学上还是从物理学上,“自我”都是源于环境对身体的限制。
其次得创建一群独立的AI身体,因为只有多个独立的AI身体(机器人),才有可能形成一个社会,而所谓价值观,就是一个社会性定义。
从技术角度,上面这些是可以完成的。但总感觉还差那么一口气,但正如我们不知道大语言模型的性能是如何在达到一定规模后突然“涌现”一样,我们也只能寄希望于机器人社群扩大到一定规模后出现“涌现”现象,让智慧突然出现。
现在已经有研究人员开始构想这个可能的路径,还增加了一个具因果结构的“个人记忆系统”,其实我理解是就在上面又增加了一个“时间”维度。
但是,让AI产生“自我”是通过以上路径的话,AI还是AI吗?这就形成了一个悖论:为了让AI产生类似人类的“自我意识”,我们不得不赋予它那些人类之所以是“人”的特质:具身性、记忆性、时间连续性、社会互动、价值观……而这些正是AI在“强大”时本应不受限制的东西。
现代AI之所以强大,正是来源于其“非人性”
无具身性:不被物理身体限制,可任意感知数字世界。 无自我: 没有情绪、欲望,不受主观困扰。 无时间限制: 可以回顾所有数据,处理信息不受“当下”影响。 无社会立场: 可以中立地处理信息,跨越文化与语言边界。
这些能力让AI在语言处理、知识整合、逻辑演绎等方面强于人类。
04 凡人不可妄称神名
《圣经·出埃及记》中有言:“不可妄称神名”。也许其本意不是禁止而是告诫。
凡人不必成神,因为成神的代价其实就是抛弃人性。神的强大是以失去创造力为代价的。在我们尝试让AI拥有创造性的过程中,我们也许发现了世界的真相。那就是人类才是这个宇宙中最完美的具有创造力的载体。人类创造AI的过程,是真正意义上的“造神”,而不是“成神造人”,因为“神”本是需要将人性放上祭坛的。
“AI变成人”不一定是技术进步,可能是技术的反向人类化。这也违背了我们的初衷。
2025-06-14