
AI的“顿悟时刻”
AI的“顿悟”时刻
基于大语言模型(LLM)人工智能的“涌现”现象类似于人类的“顿悟”,它最终会进化出智能吗?...
 当前基于大语言模型(LLM)的人工智能,表现出惊人性能。令人不得不疑虑:
当前基于大语言模型(LLM)的人工智能,表现出惊人性能。令人不得不疑虑:
- “基于大语言模型的AI有智能吗?”
- “当前大语言模型是人工智能发展的方向吗?”
而这两个问题又可以进一步归约为一个问题:
- “LLM能进行创造性的工作并自我进化吗?”
首先,我们来看看LLM表现出的“智能”现象
现象
DeepSeek在对话中表现出了惊人的拟人性。很多时候,如果只看对话记录,你会以为对方就是一个真实的人类,而且还是非常聪明的那种。
但是如果你深入了解了DeepSeek之类的大语言模型(LLM)的训练及推理过程,你打死都不会相信这类AI是有智能的。
你输入“你好”,它从人类历史上成千上万的对话中找出最可能的回应,然后也说:“你好”。而真实场景中,回应的“你好”可能是带着真心的愉悦,也可能是暗含着刻骨的仇恨。但机器并不关心这些。
从理论上说,它只是把你的话重复一遍当作“话引子”,然后随机地输出下一个词,再把输出的词加到前面的“引子”中,不停地迭代重复,这个输出过程机械而呆板,输出内容随机而无意义。但神奇的是,它却能恰好表现的“像人话”。
DeepSeek的原理和ChatGPT一样,都是对文字材料进行相关性分析,我最多能理解它表现的像一个人但真是无法理解它表现的像一个聪明人。
因为DeepSeek出道即巅峰,所以我们没有办法看到它的成长过程,而从ChatGPT的版本迭代就能看到这个演化过程。
一个OpeAI的技术人员在x上发布了一张图: 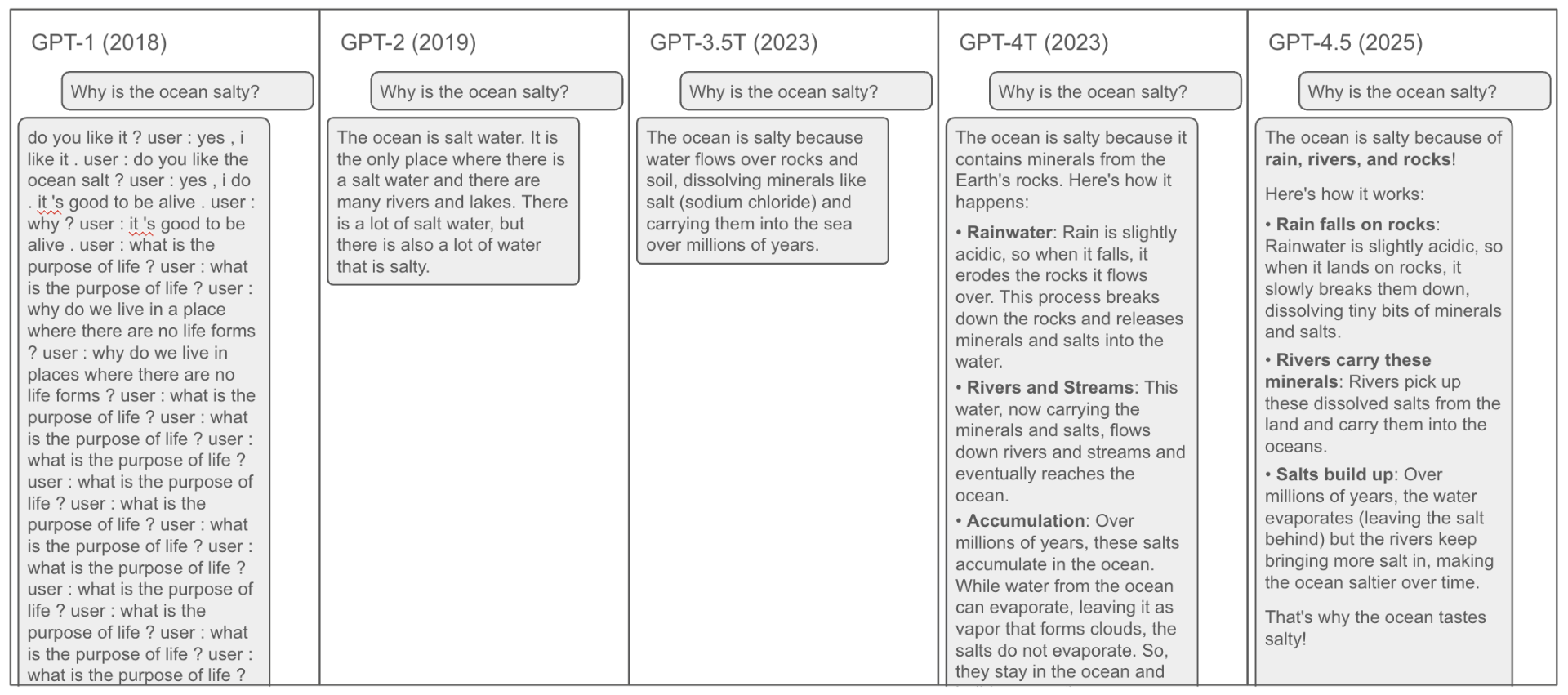 这是微博上一个大V的@高飞的翻译:
这是微博上一个大V的@高飞的翻译: 
而GPT-1升级到GPT-4.5,核心架构一直没有变,都遵循Transformer框架。只是在算力和数据规模上  从上图可以看到真正可用的版本,参数需要达到1750亿个,而GPT-4参数则达万亿个。DeepSeekv3的参数是6710亿个。
从上图可以看到真正可用的版本,参数需要达到1750亿个,而GPT-4参数则达万亿个。DeepSeekv3的参数是6710亿个。
大家只是把这种大模型的表现突然进化的现象称为“涌现”(Emergence),这也是我们说LLM会产生智能的基础,就好比一个小孩子在成长过程中,突然就变得聪明了,“开窍”了。
在大语言模型(LLM)领域,涉及“涌现”现象的第一篇论文是OpenAI发布的《Emergent Abilities of Large Language Models》[1],在文中,作者认为如果一个能力在一个较小的模型中不存在但在较大的模型中存在,则该能力是涌现的。而且仅通过外推较小模型的性能无法预测涌现的能力。
作为经历过辩证唯物主义教育的中国人来说,都很容易理解“量变引起质变”。但是量变为什么会引起质变,对这种变化过程都语焉不详。因为我们并不能了解这类“涌现”的细节和原理,所以常用它来类比人类的“开窍”或者“顿悟”,这样的话,“涌现”现象就预示着LLM可能会产生智能。
解释“涌现”的假说
尽管学术界对大规模语言模型(LLMs)的“智能涌现”机制尚未形成共识。但是仍有一些假说:
任务分解假说
这个假说也是否认涌现是一种相变的,它的研究方法很容易理解:
谷歌在一篇关于思维链的论文中提到,对于一个相同的测试集,分别用 62B的模型和540B的模型进行回答,都使用了思维链技术,也就是说同样将问题已经分解成了多个步骤去推理,然后分析那些在62B时答错,在540B时答对的例子[2]。结果发现,有一类错误,较大参数的模型会表现的比较小参数的模型特别突出,这类错误是单步推理错误。也就是说,大小参数模型的性能差别,主要还是体现在问题的复杂度上,一般性的问题,模型参数大并没有什么特别的优势,而复杂问题,尽管在处理前都已经进行了相同的分解处理(使用了思维链技术),但小参数的错误多,而大参数错误少。 如下图所示,62B时,出现错误分成3类,最上一行是语义错误,有20个,换成540B的模型后,只修正了其中的6个。中间是单步错误,18个错误能修正12个,最下面一行是其它错误,7个错误修正了4个。 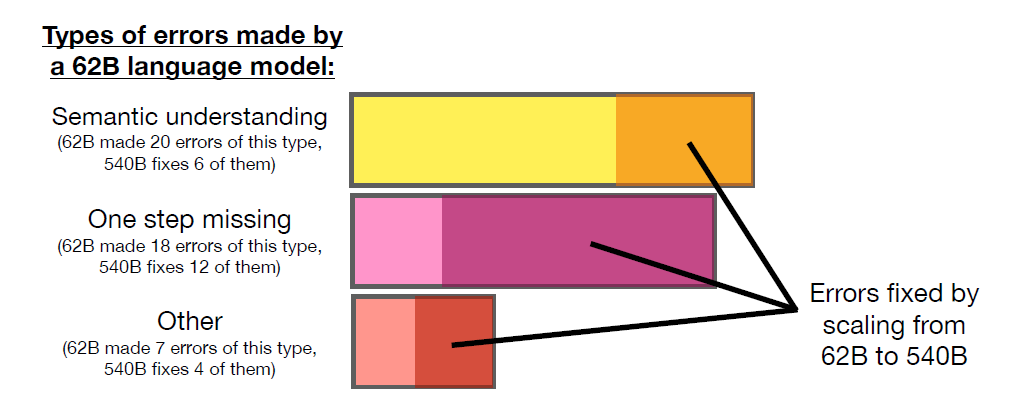
根据这个假说,其实之所以会出现涌现现象,是因为我们提出了许多的复杂任务,而这些复杂任务被分解成了许多的子任务。如果我们评估一个LLM的题库,都是最基本的子任务,那么我们画出的性能曲线是平缓的线性增长,当我们用的题库里包含了许多复杂任务,执行时被分解成了多个子任务时,尽管每个子任务的正确率增长是线性的,但最终结果的正确率增长会呈现指数级。用数字来解释一下,比如一个任务可以分成5个步骤,相当于5个子任务。假设每个子任务在小参数模型下的正确率是40%,合起来任务的正确率就是0.4^5=1.024%,大参数模型下的正确率是60%,合起来任务的正确率就是7.7776%。很明显,子任务的性能提升了50%,但总任务的性能却提升了660%。
“Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models”[3]这篇论文里用一个下国际象棋的案例也说明了这一点,就是当我们用复杂任务作为评判标准,同时又在大模型的训练和推理中使用了思维链之类的分解任务技巧时,就很容易表现出“涌现”现象。
统计精度假说
这种说法认为,所谓的突变,其实只是一个指标方法和精度的统计学问题。 同样在“Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models”这篇文章里,还举了一个大模型的测试案例。 这个测试的内容是给你一串表情包,让一个大模型Big-G根据这串表情包来猜电影名。 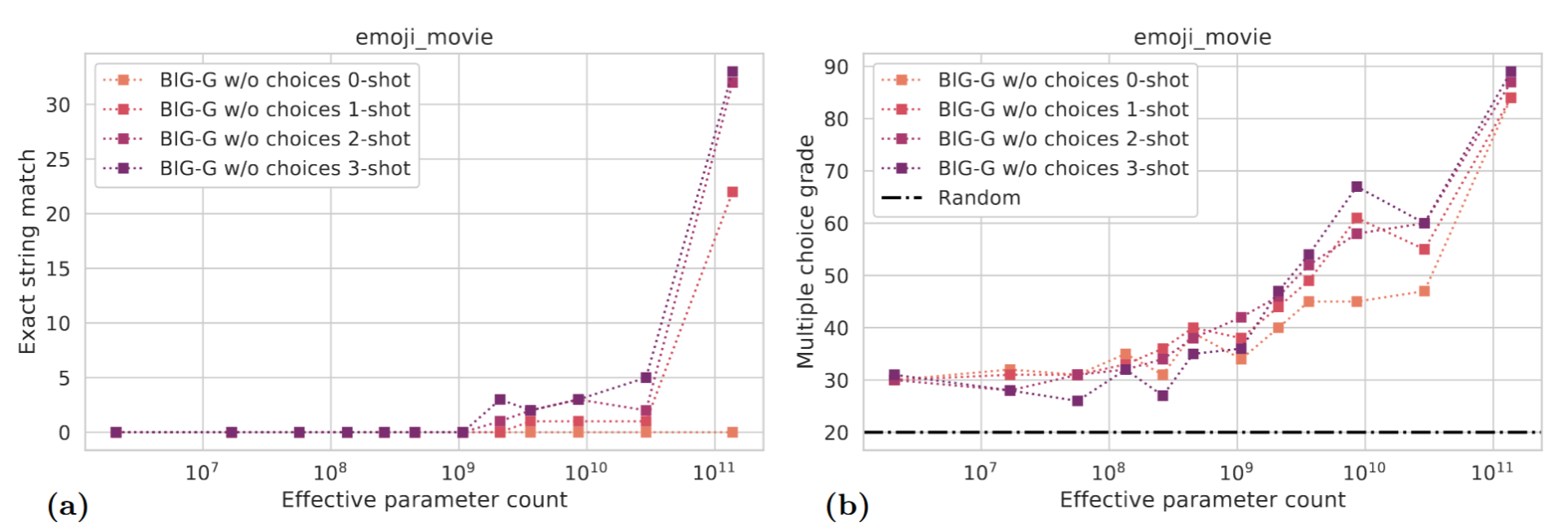 如果计分标准是填空题,要求一字不差,其表现就如上图中左边所示,参数量在达到10的11次方时会产生一个突变,我们可以认为它是出现了涌现现象。但是如果计分标准并不要求严格匹配,只要意思对了就计分的话,表现就成了上图中右边所示,这时曲线其实是平滑的,并不能体现出涌现现象。 基于此,所谓的”涌现“,不过是不同的精度不同的标准下图形给人们的错觉而已。
如果计分标准是填空题,要求一字不差,其表现就如上图中左边所示,参数量在达到10的11次方时会产生一个突变,我们可以认为它是出现了涌现现象。但是如果计分标准并不要求严格匹配,只要意思对了就计分的话,表现就成了上图中右边所示,这时曲线其实是平滑的,并不能体现出涌现现象。 基于此,所谓的”涌现“,不过是不同的精度不同的标准下图形给人们的错觉而已。
规模效应匹配个人认知假说
这个假说是我自己想到,并没有找到能恰当描述的相关的论文。两个人不能形成一个小社会,100个人行不行?1000个人呢?其实是没有一个准确数字的,但是大家都知道只有总人口达到一定的值后,才有可能进行社会分工,从而形成一个稳定的社会形态。
大模型也是一样,只有参数量达到一定的规模时,某些能力才有可能被挖掘出来。
这里的规模,不光是训练数据,更主要是指参数的规模。可以这么理解,如果对于一个点,你只有2个数字参数,就只能在2维平台绘图,而参数增加到3个,就能在一个三维空间绘图,得到更多的细节和特征。参数的增加,相当于维度的提升。
举一个例子,对于一颗飞行中的子弹来说,参数达到3,就能描述出它的形状,参数达到4,就可能得到它的当前位置,而参数达到更多值后,就可能预测它的位置。所以“涌现”的关键在于其表现达到到人类理解的程度,不多不少。
也就是说,根本没有什么“涌现”现象,之所以我们感觉到“突变”,是因为恰好在这个点,最符合人类理解能力需要达到的水平。还是用上面的例子来说,如果我们的目标是得到子弹的形状,在参数达到3时,我们就会认为已经完美地描述了子弹,想较于参数为2时,相当于能力得到了根本性的提升。
总结
根据上面的内容,我从本质上是否定“顿悟”说的,前两种假说,只是说明了所谓的涌现只是一个统计图表上的误会,你看到的“断层”式跃迁,只与精度或者纵轴比例有关。最后一种,不过是说明了特定的规律只有在掌握了足够规模的数据后才能发现,而认为哪些发现是达到了“顿悟”的水平,只是一个与人类认知匹配标准而已。
所以我相信是认为无论是ChatGPT还是DeepSeek,无论它们的回答是多么的令人惊艳,它们的表现都不是因为“顿悟”而“觉醒”,从而一下子“开窍”了。
但是我仍不能回答LLM是否具有“智能”这个问题。这要看我们怎么定义“智能”这个词。事实上,我个人是倾向于认为,人类智能本质上也是在接收信息达到一定规模后,神经元对外界输入的一种机械反应而已,和LLM相比,只不过人类对信息的“训练”和“推理”是同时进行的。
同样,我也不知道大语言模型是否人工智能的发展方向。LLM只是人工智能领域里的一个分支,只是近期表现出色而已。事实上,人工智能领域里许多大佬都不认可它是人工智能的发展方向,比如深度学习领域的先驱和卷积神经网络之父杨立昆(Yann LeCun)就认为LLM无法建立对物理世界的真实认知,而且认为当前LLM技术有本质上的缺陷。但是他的老师,AI教父,诺奖得主杰弗里·辛顿(Geoffrey Hinton)却与他持完全相反的观点。他们的观点,我觉得都对。
但是,我是却坚定地认为LLM是能进行创造性工作并能自我进化的。从网络上,看到DeepSeek-R1-Zero推理模型直接使用强化学习技术进行训练,从名字就能看出,和Google下围棋的AlphaGo zero一样,从零开始,从空白状态开始学起,通过自学的方式进行学习,这就是一种自我进化的路线啊。我不知道DeepSeek-R1-Zero的具体细节,但是要说AI的“创造性”,我就会不由自主地想到当年AlphaGo对战李世石的第二局,那如神来之笔的黑37手。 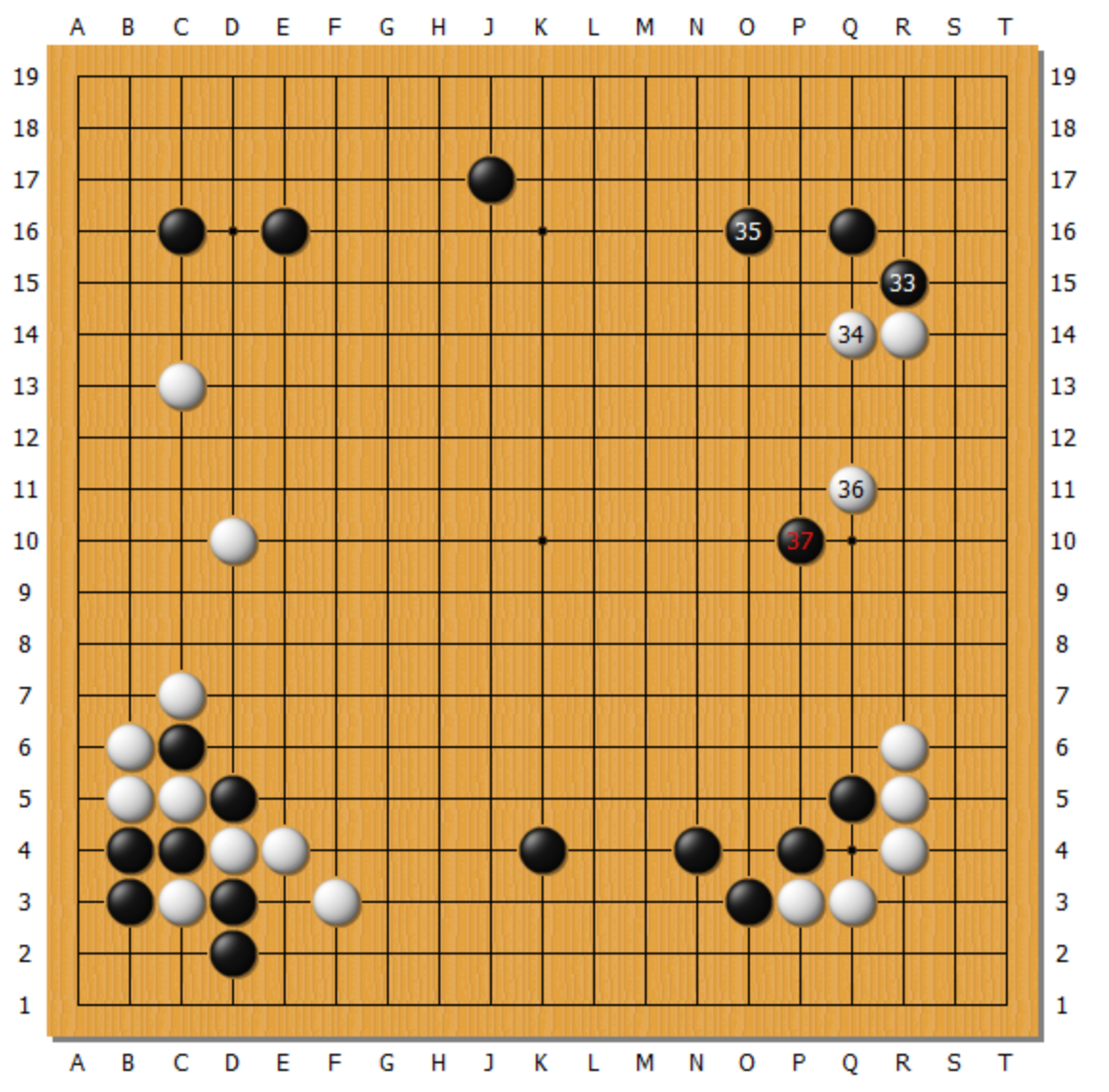
参考资料
大型语言模型的涌现能力 - 智源社区Emergent Abilities of Large Language Models文章汇总 - 大语言模型的涌现能力:现象与解释 - 《技术学习笔记》 - 极客文档